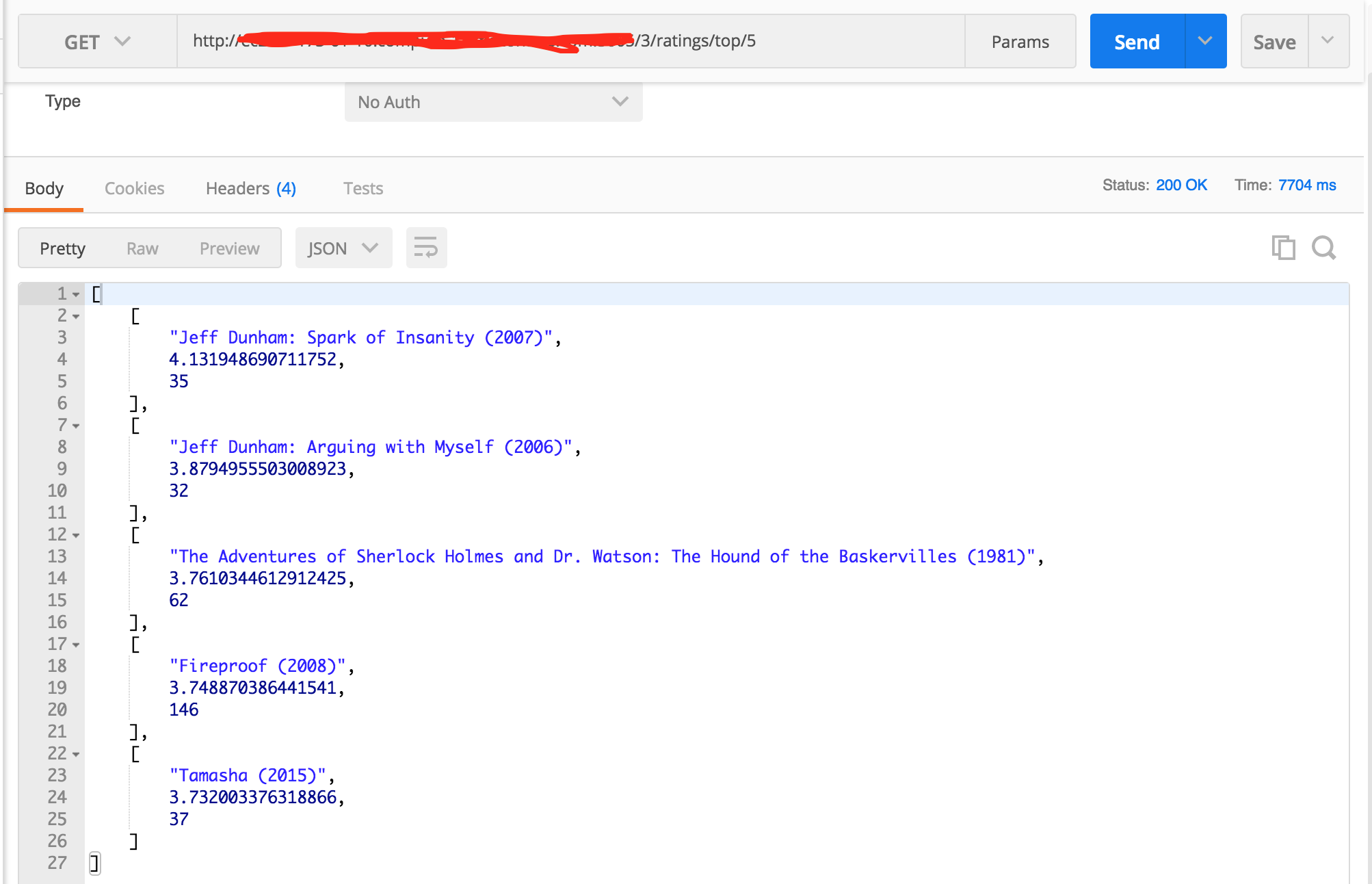
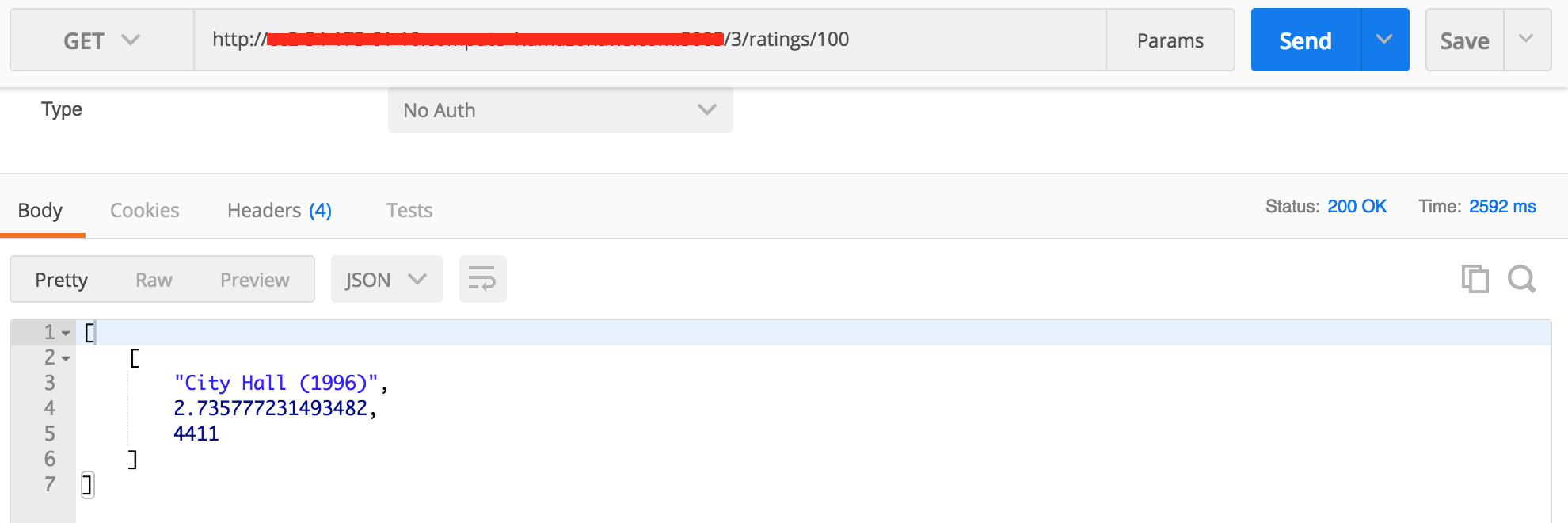
# -*- coding: utf-8 -*-fromflaskimportBlueprintfromengineimportRecommendationEnginefromflaskimportFlask,requestimportloggingimportjsonmain=Blueprint('main',__name__)logging.basicConfig(level=logging.INFO)logger=logging.getLogger(__name__)@main.route("/<int:user_id>/ratings/top/<int:count>",methods=["GET"])deftop_ratings(user_id,count):logger.debug("User %s TOP ratings requested",user_id)# 특정 유저에게 평점이 높은 상위 n개의 영화를 추천해준다.top_ratings=recommendation_engine.get_top_ratings(user_id,count)returnjson.dumps(top_ratings)@main.route("/<int:user_id>/ratings/<int:movie_id>",methods=["GET"])defmovie_ratings(user_id,movie_id):logger.debug("User %s rating requested for movie %s",user_id,movie_id)# 특정 유저에게 특정 영화에 대한 영화 평점을 알려준다.ratings=recommendation_engine.get_ratings_for_movie_ids(user_id,[movie_id])returnjson.dumps(ratings)@main.route("/<int:user_id>/ratings",methods=["POST"])defadd_ratings(user_id):"""
curl -d @/path/user_ratings.json -X POST http://[hostname:port]/0/ratings
"""# POST request 요청하여 추가적인 ratings의 정보를 가져온다.ratings_list=request.get_json(force='false')# Tuple(user_id, movie_id, rating)# 속성값의 타입을 변경해준다ratings=map(lambdax:(user_id,int(x['movie_id']),float(x['rating'])),ratings_list)# add ratings 호출recommendation_engine.add_ratings(ratings)returnjson.dumps(ratings)defcreate_app(spark_context,dataset_path):globalrecommendation_enginerecommendation_engine=RecommendationEngine(spark_context,dataset_path)app=Flask(__name__)app.register_blueprint(main)returnapp
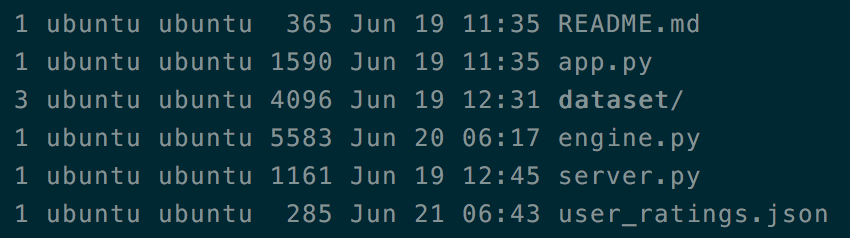
server.py
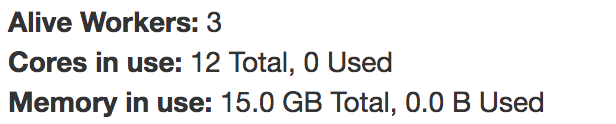
cherrypy 모듈을 사용하여 WSGI구성 및 engine(SparkContext) 및 app(flask) 초기화를 해준다.
# -*- coding: utf-8 -*-importosfrompysparkimportStorageLevelfrompyspark.mllib.recommendationimportALSimportlogginglogging.basicConfig(level=logging.INFO)logger=logging.getLogger(__name__)defget_counts_and_averages(ID_and_ratings_tuple):"""Given a tuple (movieID, ratings_iterable)
returns (movieID, (ratings_count, ratings_avg))
"""nratings=len(ID_and_ratings_tuple[1])# Tuple(movieID, (ratings_count, ratings_avg)) 반환returnID_and_ratings_tuple[0],(nratings,float(sum(xforxinID_and_ratings_tuple[1]))/nratings)classRecommendationEngine:"""A movie recommendation engine
"""def__count_and_average_ratings(self):"""Updates the movies ratings counts from
the current data self.ratings_RDD
"""logger.info("Counting movie ratings...")"""
union 연산된 RDD (user_id, movie_id, rating)에 대해
(movie_id, rating)속성을 groupByKey count한 결과와 movie_id를 update한다.
-> Tuple(movie_id, ratings count)
"""movie_ID_with_ratings_RDD=self.ratings_RDD.map(lambdax:(x[1],x[2])).groupByKey()movie_ID_with_avg_ratings_RDD=movie_ID_with_ratings_RDD.map(get_counts_and_averages)self.movies_rating_counts_RDD=movie_ID_with_avg_ratings_RDD.map(lambdax:(x[0],x[1][0]))def__train_model(self):"""Train the ALS model with the current dataset
"""logger.info("Training the ALS model...")self.model=ALS.train(self.ratings_RDD,self.rank,seed=self.seed,iterations=self.iterations,lambda_=self.regularization_parameter)logger.info("ALS model built!")def__predict_ratings(self,user_and_movie_RDD):"""Gets predictions for a given (userID, movieID) formatted RDD
Returns: an RDD with format (movieTitle, movieRating, numRatings)
"""predicted_RDD=self.model.predictAll(user_and_movie_RDD)predicted_rating_RDD=predicted_RDD.map(lambdax:(x.product,x.rating))# join 연산을 한다.predicted_rating_title_and_count_RDD= \
predicted_rating_RDD.join(self.movies_titles_RDD).join(self.movies_rating_counts_RDD)# Tuple(movieTitle, movieRating, numRatings)을 반환한다.predicted_rating_title_and_count_RDD= \
predicted_rating_title_and_count_RDD.map(lambdar:(r[1][0][1],r[1][0][0],r[1][1]))returnpredicted_rating_title_and_count_RDDdefadd_ratings(self,ratings):"""Add additional movie ratings in the format (user_id, movie_id, rating)
"""# RDD 생성new_ratings_RDD=self.sc.parallelize(ratings)# union 연산을 한다.self.ratings_RDD=self.ratings_RDD.union(new_ratings_RDD)# __count_and_average_ratings 호출self.__count_and_average_ratings()# __train_model 호출self.__train_model()returnratingsdefget_ratings_for_movie_ids(self,user_id,movie_ids):"""Given a user_id and a list of movie_ids, predict ratings for them
"""requested_movies_RDD=self.sc.parallelize(movie_ids).map(lambdax:(user_id,x))# predicted ratings에 대해 collectratings=self.__predict_ratings(requested_movies_RDD).collect()returnratingsdefget_top_ratings(self,user_id,movies_count):"""Recommends up to movies_count top unrated movies to user_id
"""# 평가가 되지 않은 movies에 대한 user_id의 Tuple(userID, movieID)값을 가져온다.user_unrated_movies_RDD=self.ratings_RDD.filter(lambdarating:notrating[0]==user_id) \
.map(lambdax:(user_id,x[0])).distinct()# predicted ratings 호출ratings=self.__predict_ratings(user_unrated_movies_RDD) \
.filter(lambdar:r[2]>=25).takeOrdered(movies_count,key=lambdax:-x[1])returnratingsdef__init__(self,sc,dataset_path):"""Init the recommendation engine given a Spark context and a dataset path
"""logger.info("Starting up the Recommendation Engine: ")self.sc=sclogger.info("Loading Ratings data...")# ratings.csv 로드ratings_file_path=os.path.join(dataset_path,'ratings.csv')ratings_raw_RDD=self.sc.textFile(ratings_file_path)ratings_raw_data_header=ratings_raw_RDD.take(1)[0]"""
head -n 5 ratings.csv
userId,movieId,rating,timestamp
1,122,2.0,945544824
1,172,1.0,945544871
1,1221,5.0,945544788
1,1441,4.0,945544871
"""# ratings.csv을 정제 및 persist 처리self.ratings_RDD=ratings_raw_RDD \
.filter(lambdaline:line!=ratings_raw_data_header) \
.map(lambdaline:line.split(",")) \
.map(lambdatokens:(int(tokens[0]),int(tokens[1]),float(tokens[2])))\
.persist(storageLevel=StorageLevel.MEMORY_ONLY)logger.info("Loading Movies data...")# movies.csv 로드movies_file_path=os.path.join(dataset_path,'movies.csv')movies_raw_RDD=self.sc.textFile(movies_file_path)movies_raw_data_header=movies_raw_RDD.take(1)[0]"""
head -n 5 movies.csv
movieId,title,genres
1,Toy Story (1995),Adventure|Animation|Children|Comedy|Fantasy
2,Jumanji (1995),Adventure|Children|Fantasy
3,Grumpier Old Men (1995),Comedy|Romance
4,Waiting to Exhale (1995),Comedy|Drama|Romance
"""# movie_raw_RDD 파싱 및 persist 처리self.movies_RDD=movies_raw_RDD \
.filter(lambdaline:line!=movies_raw_data_header) \
.map(lambdaline:line.split(",")) \
.map(lambdatokens:(int(tokens[0]),tokens[1],tokens[2])) \
.persist(storageLevel=StorageLevel.MEMORY_ONLY)# movies_titles_RDD 파싱 및 persist 처리self.movies_titles_RDD=self.movies_RDD.map(lambdax:(int(x[0]),x[1])) \
.persist(storageLevel=StorageLevel.MEMORY_ONLY)# count_and_average_ratings 호출self.__count_and_average_ratings()# 하이퍼 파라미터 설정 및 train_model 호출self.rank=8self.seed=5Lself.iterations=10self.regularization_parameter=0.1self.__train_model()