importorg.apache.spark.streaming.dstream.DStreamimportorg.apache.spark.streaming.twitter.TwitterUtilsimportorg.apache.spark.streaming.{Seconds,StreamingContext}importorg.apache.spark.{SparkConf,SparkContext}objectSentimentScoreextendsApp{importUtils._valconf=newSparkConf().setAppName("spark-twitter-stream-example").setMaster("local[*]")valsc=newSparkContext(conf)valssc=newStreamingContext(sc,batchDuration=Seconds(10))// DStream[Status] 생성
valtweets=TwitterUtils.createStream(ssc,None)// 각 파일을 읽어 broadcast 변수에 담는다.
valuselessWords=sc.broadcast(load("/stop-words.dat"))valpositiveWords=sc.broadcast(load("/pos-words.dat"))valnegativeWords=sc.broadcast(load("/neg-words.dat"))// 튜플타입으로 text와 공백을 제거한 Sentence 생성
valtextAndSentences:DStream[(TweetText, Sentence)]=tweets.map(_.getText).map(tweetText=>(tweetText,wordsOf(tweetText)))// Sentence 데이터 정제 => .dat에 명시된 단어를 얻기 위해서
valtextAndMeaningfulSentences:DStream[(TweetText, Sentence)]=textAndSentences.mapValues(toLowercase).mapValues(keepActualWords).mapValues(words=>keepMeaningfulWords(words,uselessWords.value)).filter{case(_,sentence)=>sentence.length>0}// xx.dat에 명시된 positive, negative words에 대해 각 합을 구한다.
valtextAndNonNeutralScore:DStream[(TweetText, Int)]=textAndMeaningfulSentences.mapValues(sentence=>computeScore(sentence,positiveWords.value,negativeWords.value)).filter{case(_,score)=>score!=0}// textAndNonNeutralScore.map(makeReadable).print
// negativeWords의 스코어(합)가 높은 순서대로 정렬을 한다.
valtweetscores=textAndNonNeutralScore.map{case(tweetText,score)=>(score,tweetText)}.transform(_.sortByKey(true)).map{case(score,tweetText)=>(tweetText,score)}.map(makeReadable)// 출력
tweetscores.print// s3에 저장
tweetscores.saveAsTextFiles("s3n://path")ssc.start()ssc.awaitTermination()}
유틸리티 코드
importtwitter4j.Statusimportscala.io.{AnsiColor,Source}objectUtils{// type alias을 통해 타입을 명시해준다. => type safe에 좋다.
typeTweet=StatustypeTweetText=StringtypeSentence=Seq[String]privatedefformat(n:Int):String=f"$n%2d"privatedefwrapScore(s:String):String=s"[ $s ] "privatedefmakeReadable(n:Int):String=if(n>0)s"${AnsiColor.GREEN + format(n) + AnsiColor.RESET}"elseif(n<0)s"${AnsiColor.RED + format(n) + AnsiColor.RESET}"elses"${format(n)}"privatedefmakeReadable(s:String):String=s.takeWhile(_!='\n').take(80)+"..."defmakeReadable(sn:(String,Int)):String=snmatch{case(tweetText,score)=>s"${wrapScore(makeReadable(score))}${makeReadable(tweetText)}"}defload(resourcePath:String):Set[String]={valsource=Source.fromInputStream(getClass.getResourceAsStream(resourcePath))valwords=source.getLines.toSetsource.close()words}defwordsOf(tweet:TweetText):Sentence=tweet.split(" ")deftoLowercase(sentence:Sentence):Sentence=sentence.map(_.toLowerCase)defkeepActualWords(sentence:Sentence):Sentence=sentence.filter(_.matches("[a-z]+"))defextractWords(sentence:Sentence):Sentence=sentence.map(_.toLowerCase).filter(_.matches("[a-z]+"))defkeepMeaningfulWords(sentence:Sentence,uselessWords:Set[String]):Sentence=sentence.filterNot(word=>uselessWords.contains(word))defcomputeScore(words:Sentence,positiveWords:Set[String],negativeWords:Set[String]):Int=words.map(word=>computeWordScore(word,positiveWords,negativeWords)).sumdefcomputeWordScore(word:String,positiveWords:Set[String],negativeWords:Set[String]):Int=if(positiveWords.contains(word))1elseif(negativeWords.contains(word))-1else0}
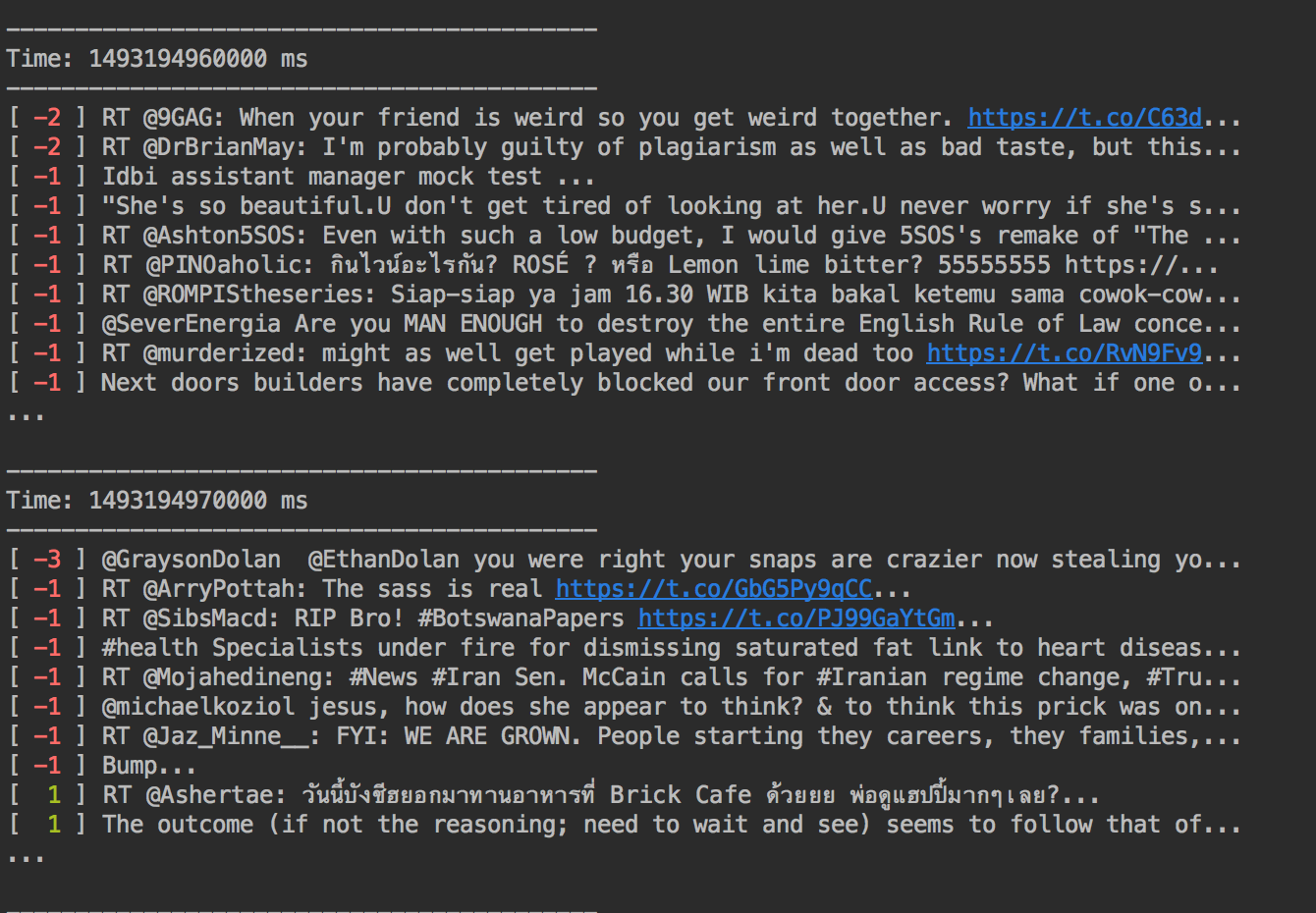
추출 결과
S3 저장
회고
적재된 S3파일을 활용하여 dataFrame을 통해 분석을 하여 추가적인 분석을 해봐야겠다.