1. 공개 스트림(Public steam): 트위터에 공개된 데이터 스트림으로 특정 사용자나 특정 주제와 관련된 데이터를 수집하여 데이터 마이닝에 적합하다.
2. 사용자 스트림(User stream): 한명의 특정 사용자와 관련된 데이터 스트림
3. 사이트 스트림(Site stream): 다수의 사용자를 대신해서 트위터에 접속한 서버를 위한 데이터 스트림
Apache Bahir은 다양한 분산 분석 플랫폼에 대한 확장 기능을 제공하며,
다양한 스트리밍 커넥터 및 SQL 데이터의 도달 범위를 확장해줍니다.
트위터 OAuth
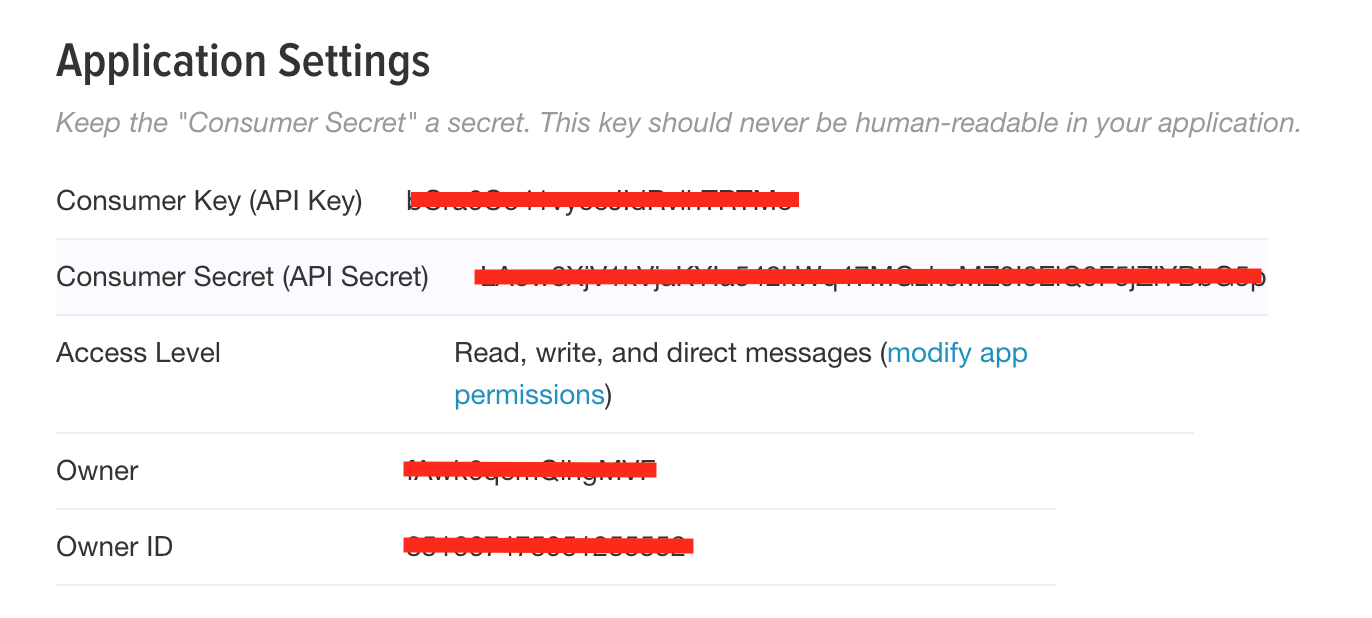
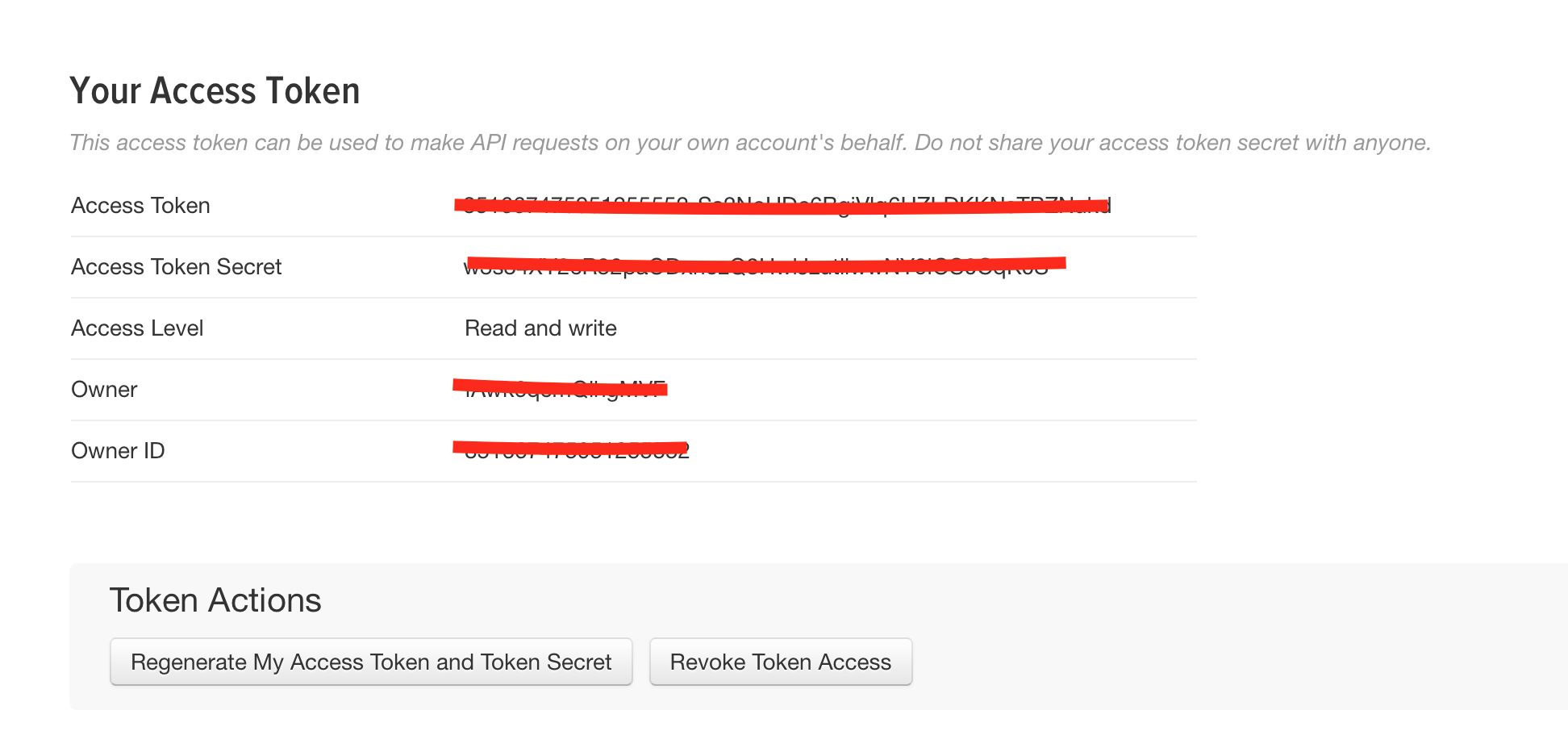
https://apps.twitter.com에 접속 하여 OAuth 인증을 한 뒤에 App계정을 만들고
Customer Key, Customer Secret, Access Token, Access Token Secret 정보를 얻는다.
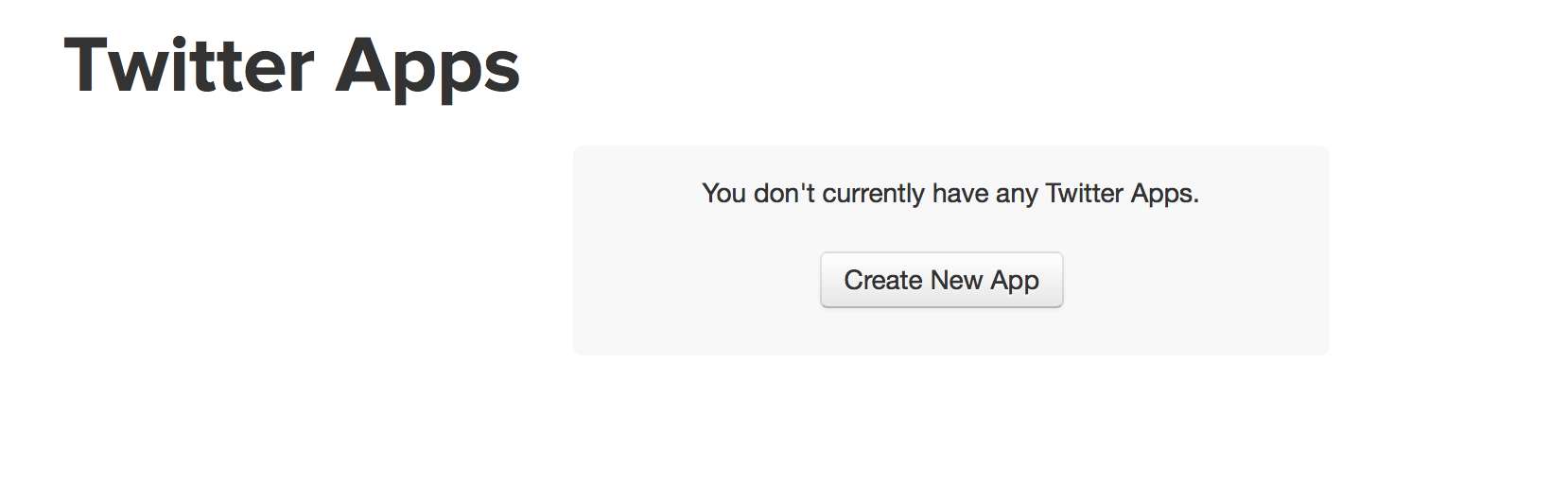
앱 만들기
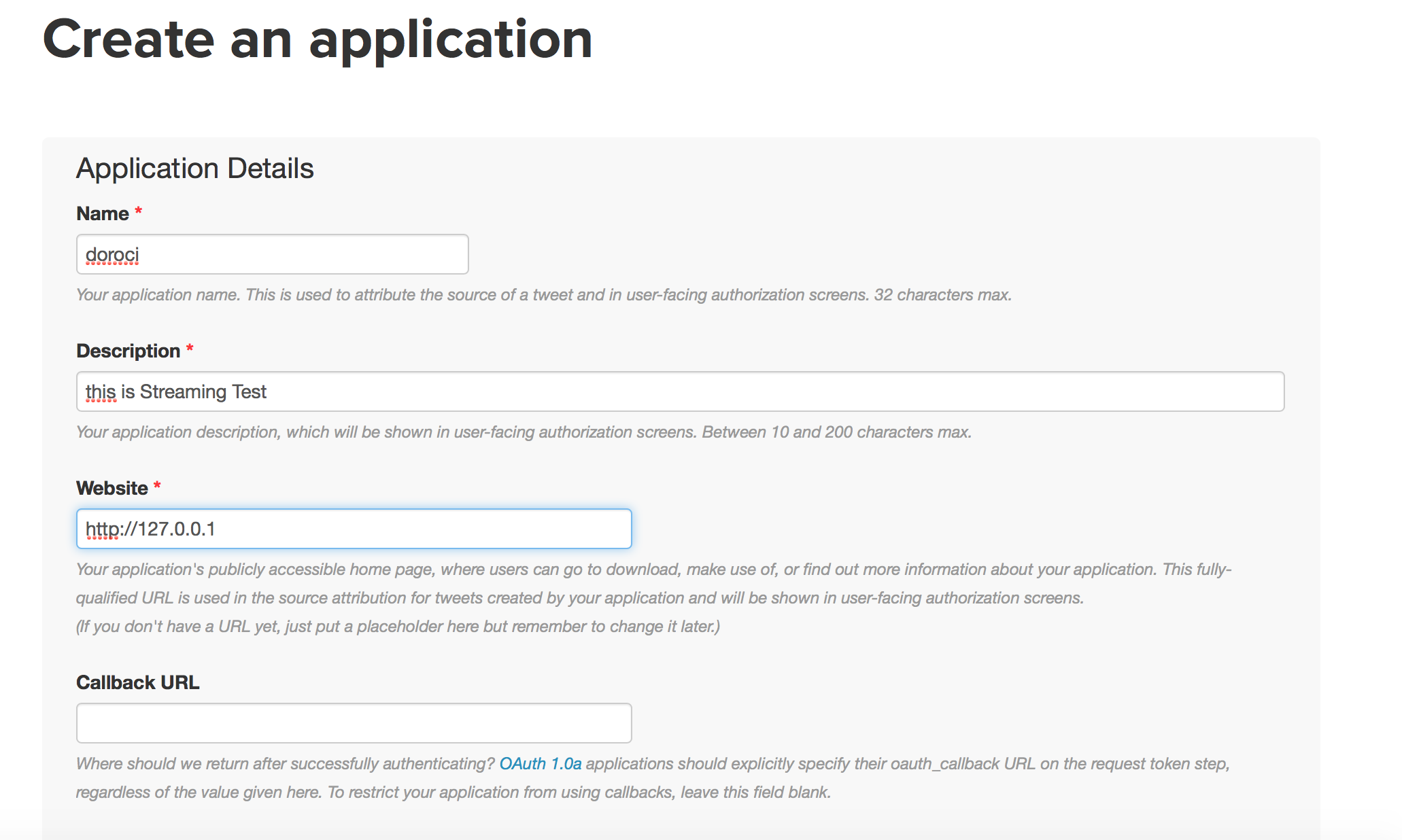
앱 정보 추가
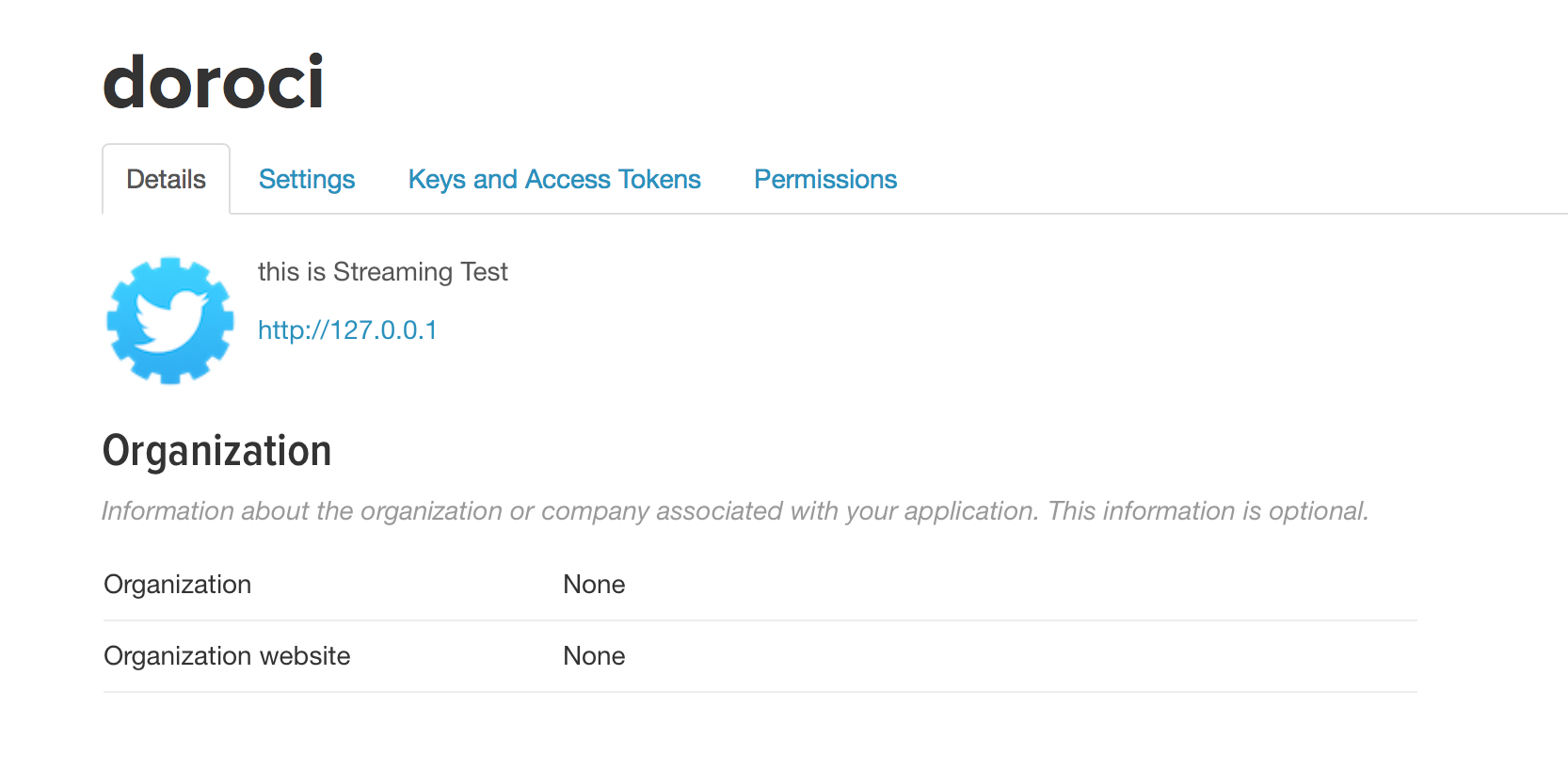
Key and Access Tokens 탭으로 이동
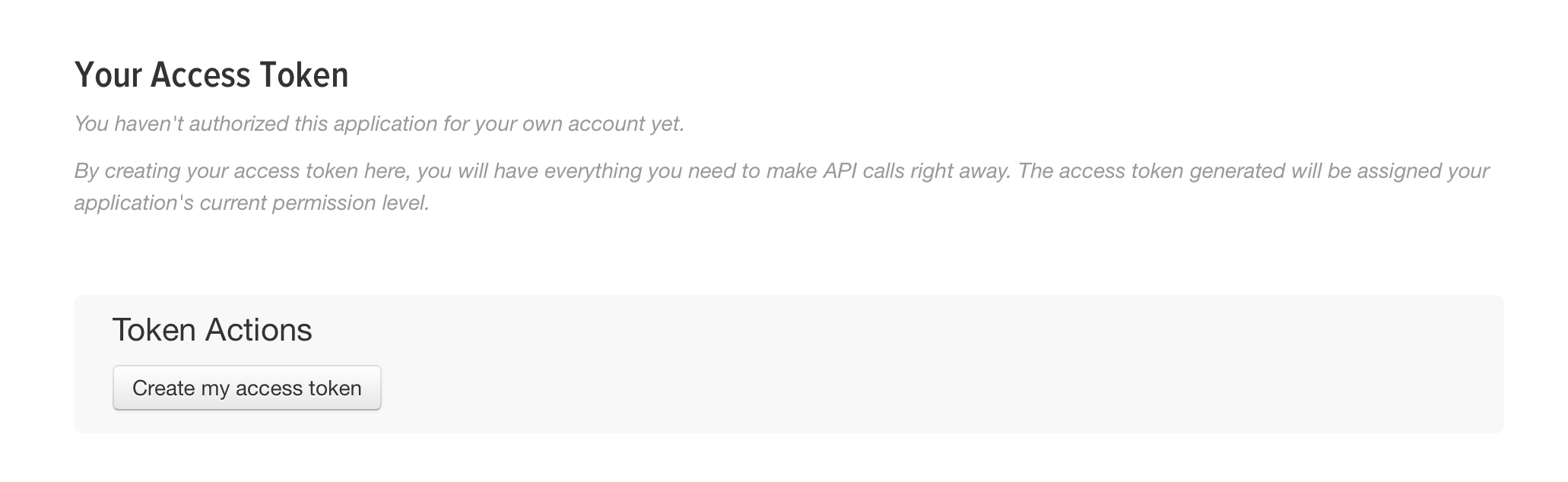
토큰 생성
커스텀 정보
토큰 정보
라이브러리 추가
//sbt Dependency 추가
libraryDependencies++=Seq("org.apache.spark"%%"spark-streaming"%"2.0.0","org.apache.bahir"%"spark-streaming-twitter_2.11"%"2.0.0","org.twitter4j"%"twitter4j-core"%"4.0.4","org.twitter4j"%"twitter4j-stream"%"4.0.4",)
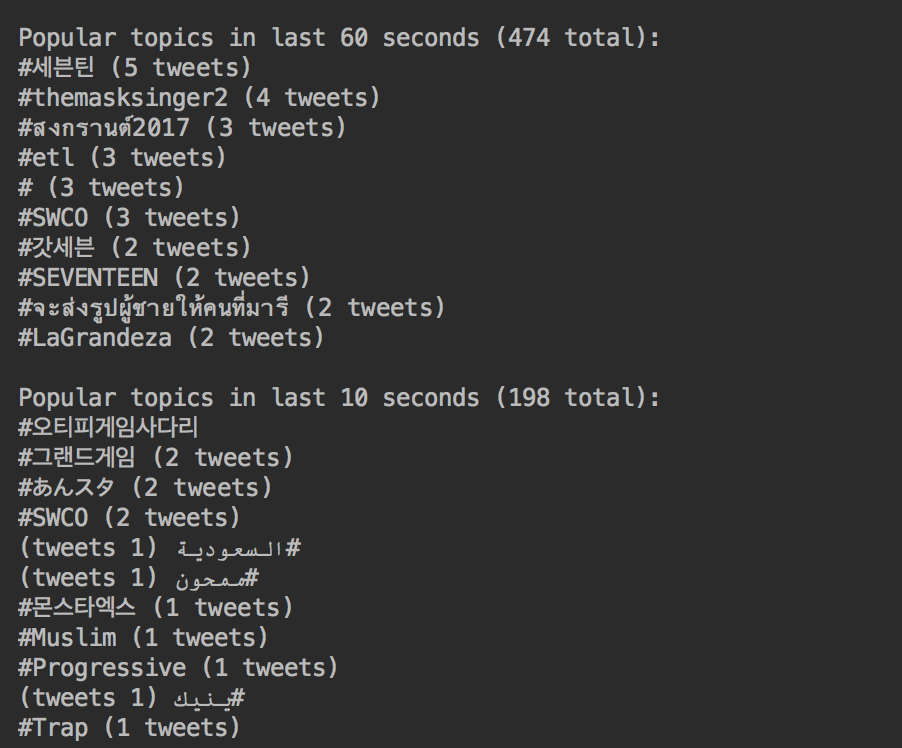
인기있는 해시태그 가져오는 예제
objectPopularTagsextendsApp{valconsumerKey="consumerKey 정보추가"valconsumerSecret="consumerSecret 정보추가"valaccessToken="accessToken 정보 추가"valaccessTokenSecret="accessTokenSecret 정보 추가"// twiiter OAuth 설정
System.setProperty("twitter4j.oauth.consumerKey",consumerKey)System.setProperty("twitter4j.oauth.consumerSecret",consumerSecret)System.setProperty("twitter4j.oauth.accessToken",accessToken)System.setProperty("twitter4j.oauth.accessTokenSecret",accessTokenSecret)valsparkConf=newSparkConf().setAppName("TwitterPopularTags").setMaster("local[*]")valssc=newStreamingContext(sparkConf,Seconds(10))valstream=TwitterUtils.createStream(ssc,None)// TwitterStream에서 text를 가져와 공백제거 및 해시태그(#)로 시작하는
// element(요소)를 필터링을 한다.
valhashTags=stream.flatMap(_.getText.split(" ").filter(_.startsWith("#")))// hasTag를 (_ ,1)형식으로 변환하고
// 60초마다 reduceByKeyAndWindow 연산을 하여 내림차순으로 정렬
valtopCounts60=hashTags.map((_,1)).reduceByKeyAndWindow(_+_,Seconds(60)).map{case(topic,count)=>(count,topic)}.transform(_.sortByKey(false))valtopCounts10=hashTags.map((_,1)).reduceByKeyAndWindow(_+_,Seconds(10)).map{case(topic,count)=>(count,topic)}.transform(_.sortByKey(false))// 인기있는 해시태그 출력
topCounts60.foreachRDD(rdd=>{valtopList=rdd.take(10)println(s"\nPopular topics in last 60 seconds (${rdd.count} total): ")topList.foreach{case(count,tag)=>println(s"${tag} (${count} tweets)")}})topCounts10.foreachRDD(rdd=>{valtopList=rdd.take(10)println(s"\nPopular topics in last 10 seconds (${rdd.count} total):")topList.foreach{case(count,tag)=>println(s"${tag} (${count} tweets)")}})ssc.start(ssc.awaitTermination()}