April
7th,
2017
스파크 튜닝 관련 자료
데이터셋 다운로드
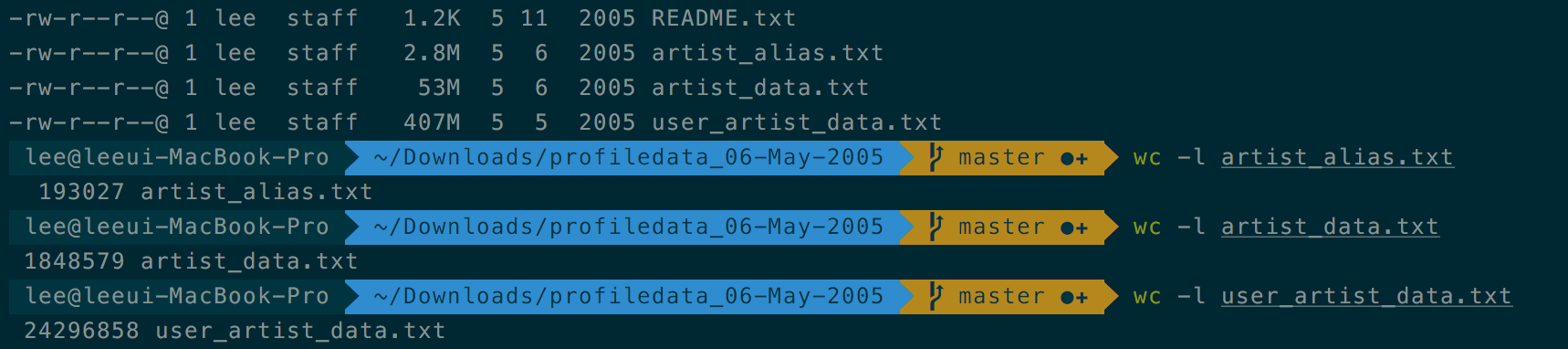
http://www-etud.iro.umontreal.ca/~bergstrj/audioscrobbler_data.html
소스 코드
- 책(3장 예제) - http://www.hanbit.co.kr/store/books/look.php?p_code=B6586238890
- https://github.com/sryza/aas/blob/1st-edition/ch03-recommender/src/main/scala/com/cloudera/datascience/recommender/RunRecommender.scala
튜닝포인트
상단의 [Tuning spark]링크를 타고 들어가면 튜닝에 관한 제공해주는 정보이다.
- Data Serialization
- Memory Tuning
- Memory Management Overview
- Determining Memory Consumption
- Tuning Data Structures
- Serialized RDD Storage
- Garbage Collection Tuning
- Other Considerations
- Level of Parallelism
- Memory Usage of Reduce Tasks
- Broadcasting Large Variables
- Data Locality
테스트 환경
- AWS EC2 인스턴스 타입: m4.4xlarge(core-16G, memory-64G)
- 스파크 스탠드얼론: 워커 인스턴스 - 4개, 워커당 코어 - 4개, 워커당 메모리 - 15G

이번 튜닝의 목적은 일반적인 튜닝의 관점에서 최소한의 튜닝으로 실행시간을 단축 시키고자 하는 것이기 때문에
로직마다의 세부적인 튜닝에 대해서는 다루지 않았습니다.
(Data Serialization, Garbage Collection Tuning, Data Locality)
또한 테스트를 위해 디스크 사용량을 최소화 하기 위해 메모리를 설정해 줬습니다.(튜닝 포인트를 줄이고자 ^^)
그리고 소스 상에서 캐시나 Broadcasting하는 부분이 있기 때문에 실제로 튜닝한 부분은
"Level of Parallelism - RDD 파티션 설정"에 관한 부분 입니다.
val rawUserArtistData = sc.textFile(base + "user_artist_data.txt", "파티션수")
val rawArtistData = sc.textFile(base + "artist_data.txt", "파티션수")
val rawArtistAlias = sc.textFile(base + "artist_alias.txt", "파티션수")
preparation(rawUserArtistData, rawArtistData, rawArtistAlias)
model(sc, rawUserArtistData, rawArtistData, rawArtistAlias)
evaluate(sc, rawUserArtistData, rawArtistAlias)
recommend(sc, rawUserArtistData, rawArtistData, rawArtistAlias)Level of Parallelism
In general, we recommend 2-3 tasks per CPU core in your cluster.
일반적으로 파티션 설정 숫자를 core * 2 ~ 3배를 추천하기 때문에
16 * n의 값으로 설정해주었습니다.
수행 결과 - 파티션 설정 X
수행시간: 19분

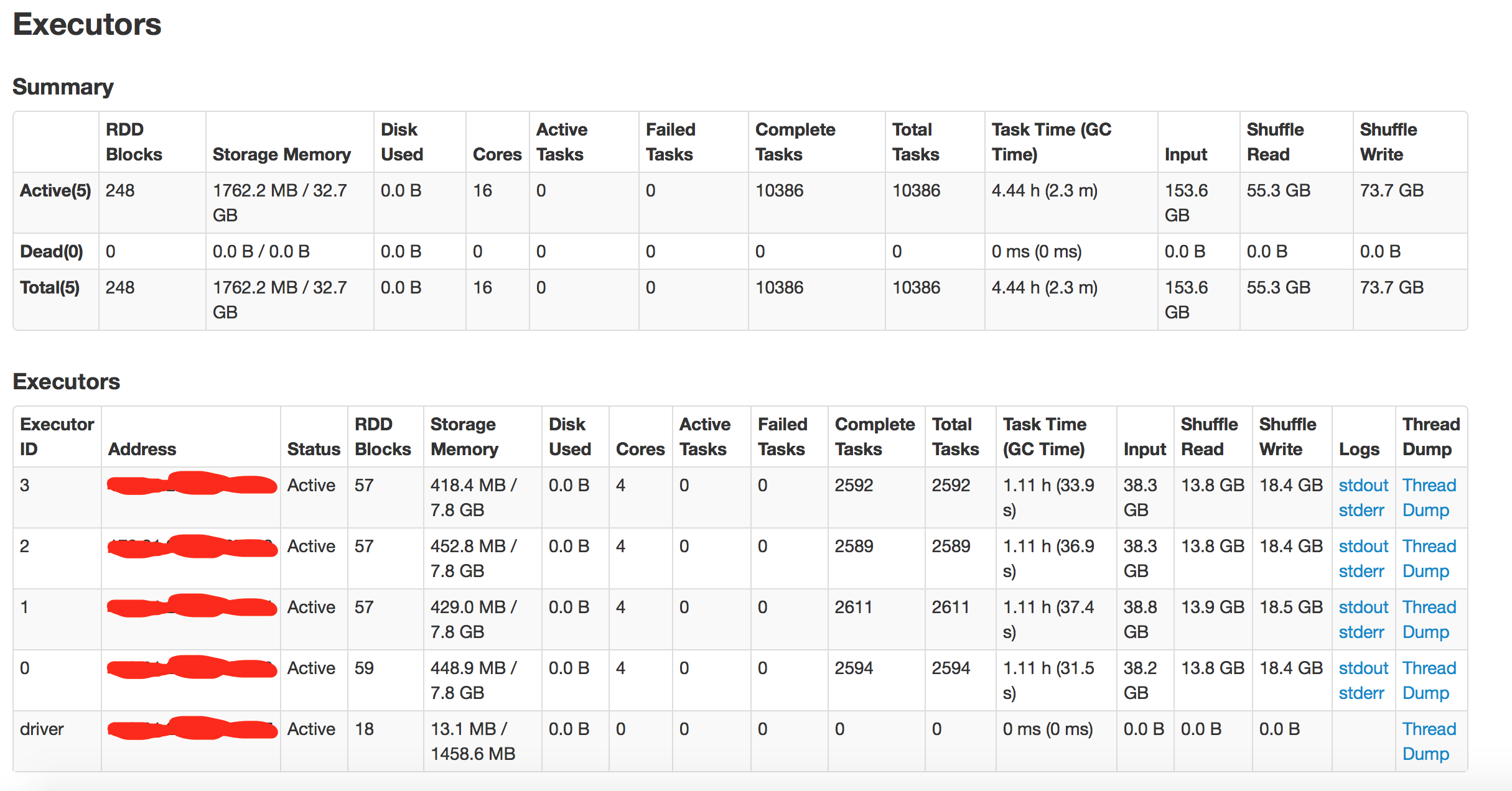
수행 결과 - 파티션 설정 4
수행시간: 43분

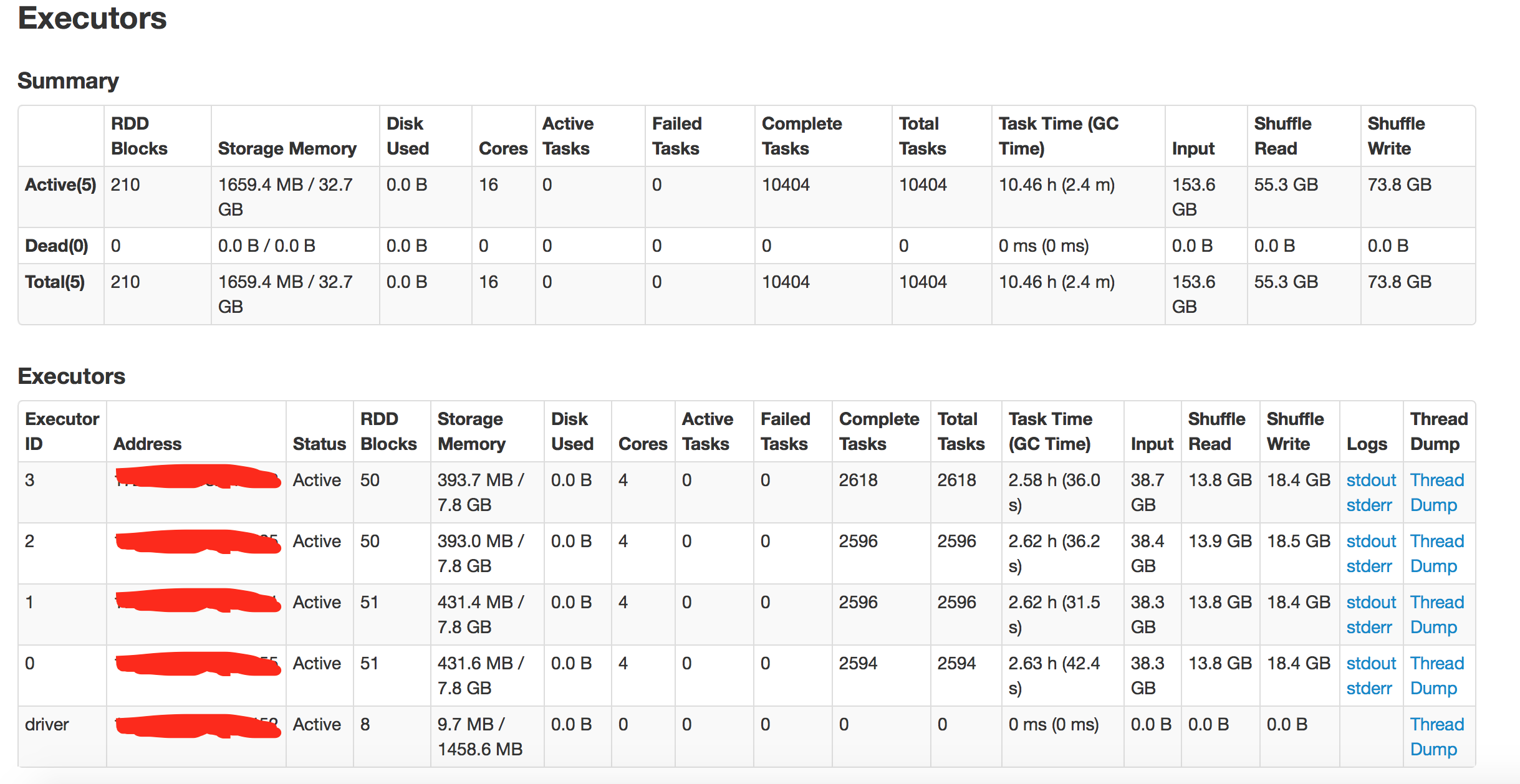
수행 결과 - 파티션 설정 16*1
수행시간: 18분
수행 결과 - 파티션 설정 16*2
수행시간: 18분
수행 결과 - 파티션 설정 16*3
수행시간: 21분
수행 결과 분석
참고로 파티션 설정을 하지 않을 경우 - 서버의 코어 수와 클러스터 모드에 따라 다르므로 잘 확인 하셔야 합니다.


1. 파티션 설정(X): 19분
2. 파티션 설정(4): 43분
3. 파티션 설정(16*1): 19분
4. 파티션 설정(16*2): 18분
5. 파티션 설정(16*3): 21분
1번에 비해 3번,4번이 수행시간이 단축된 결과를 볼 수 있습니다.
2번 처럼 파티션가 적거나 5번처럼 파티션 숫자가 너무 많으면 오히려 성능이 떨어지는 현상이 발생합니다.
따라서 적절한 파티션 설정이 튜닝 포인트 중 하나의 요소 라고 생각합니다.