March
3rd,
2017
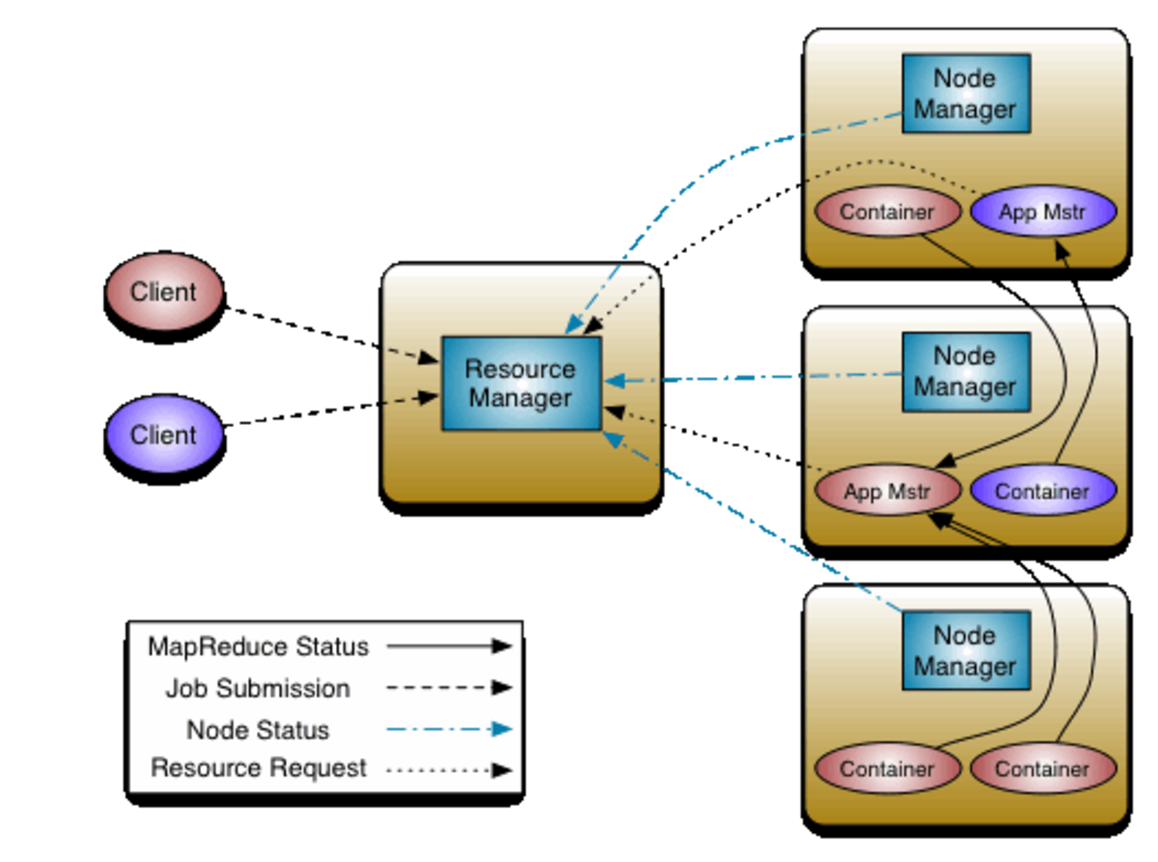
얀 클러스터 구조
우분투 인스턴스 설정

1. sudo vim /etc/hosts 실행하여 master/slave 머신의 호스트네임 설정.
ex) 192.xxx.xxx.x masternode
192.xxx.xxx.x datanode1
(호스트네임 설정을 하여 유용하게 사용하기 위함)
2. 각 머신 마다 ssh 설정
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
(참조 : https://opentutorials.org/module/432/3742)
하둡 설치
1. 하둡 다운로드
http://hadoop.apache.org/releases.html#Download
(스파크의 하둡버전과 맞춰서 선택)
2. core-site.xml 설정
<configuration>
<property>
<name>fs.defaultFS</name>
<value>마스터녿호스트명:9000</value>
</property>
</configuration>
3. hdfs-site.xml 설정
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>(네임노드경로설정)/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>(데이터노드경로설정)/datanode</value>
</property>
<proprty>
<name>dfs.namenode.checkpoint.dir</name>
<value>(네임세컨더리경로설정)/namesecondary</value>
</proprty>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
4. mapred-site.xml 설정
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>(멥리듀스 로컬 설정)/mapred</value>
</property>
<property>
<name>mapred.system.dir</name>
<value>(맵리듀스 시스템 디렉토리)/mapred</value>
</property>
</configuration>
5. yarn-site.xml 설정
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>마스터노드 호스트명/value>
</property>
</configuration>
6.hadoop-env.sh 설정
export HADOOP_HOME=/../hadoop/2.7.3
export HADOOP_COMMON_LIB_NATIVE_DIR=/../hadoop/2.7.3/share/hadoop/common/lib
export HADOOP_CONF_DIR=/../hadoop/2.7.3
7. ~/.bashrc 설정
export HADOOP_HOME=/../hadoop/2.7.3
export HADOOP_CONF_DIR=/../hadoop/2.7.3
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HAOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
8. master/slave 노드 설정
* $HADOOP_HOME/etc/hadoop/slave
ex) datanode1
datanode2
datanode3
* $HADOOP_HOME/etc/hadoop/master
ex) masternode
* zookeeper사용시 설정할 필요없음
9. 파일 소유권
sudo chown -R ubuntu:ubuntu FilePath
sudo명령어를 사용하여 파일권한이 root일경우 dependency한 파읽을 읽다가 문제가 생길수 있으니
설정을 하고 실행을 할때 문제가 생길 시 파일 소유권을 확인하는 것을 추천.
10. 파일 시스템 모드
설정을 하고 실행을 할때 문제가 생길 시 파일 시스템 모드를 확인하는 것을 추천.
참조 : https://ko.wikipedia.org/wiki/Chmod
하둡 클러스터 실행
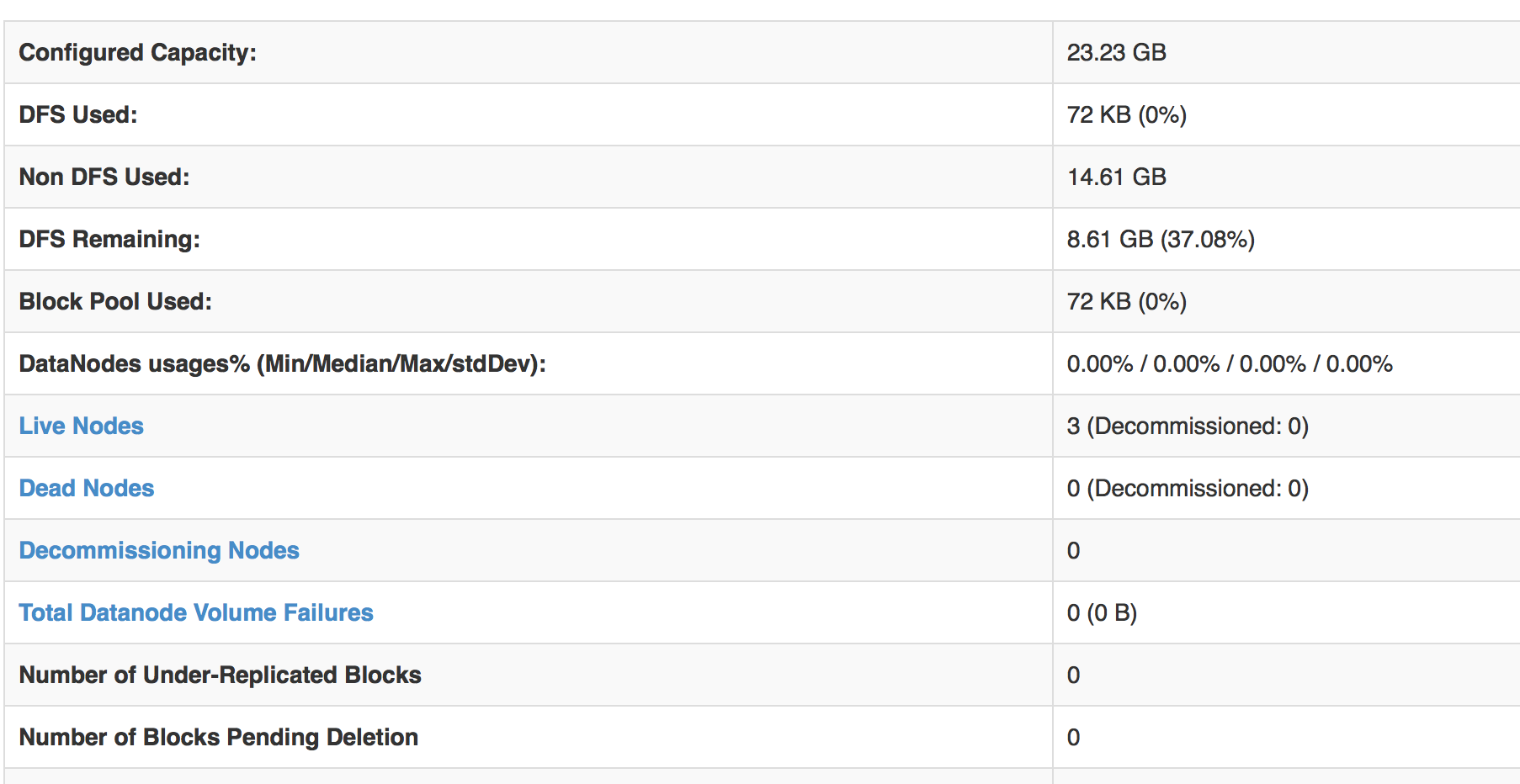
1. $HADOOP_HOME/sbin/start-dfs.sh
* 각 노드마다 jps 명령어를 사용하여 모듈확인
masternode : namenode & nameSecondaryNameNode
datanode : datanode
* masternode:50070 접속하여 live node 확인
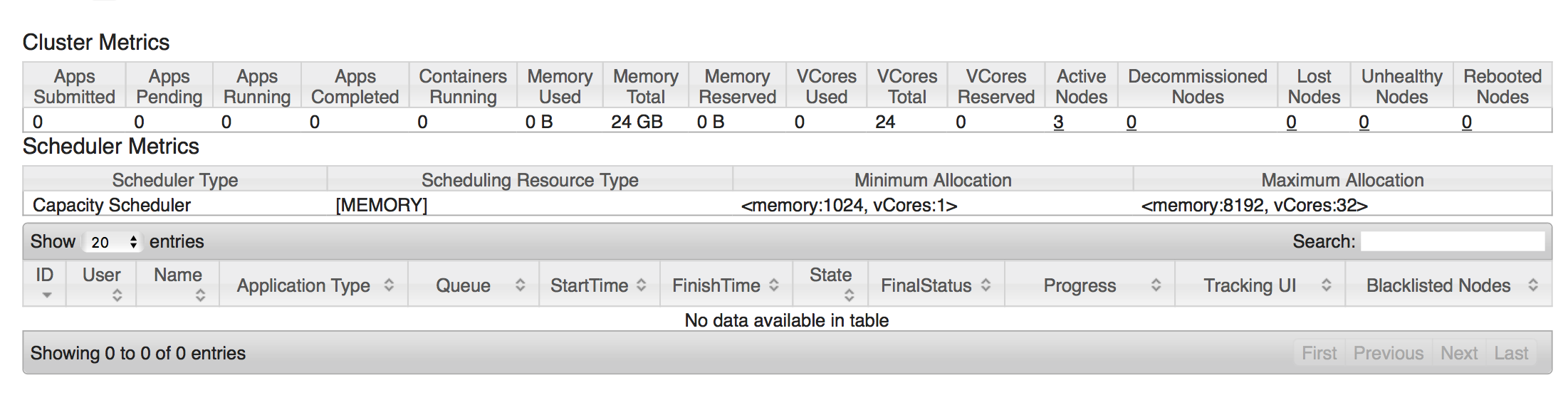
2. $HADOOP_HOME/sbin/start-yarn.sh
* masternode:8088 접속하여 yarn-site 확인
hdfs 생성
hdfs에 csv파일을 올려서 테스트할 예정
* hdfs dfs -mkdir /user
* hdfs dfs -mkdir /user/ubuntu(유저명)
* hdfs dfs -put /../ratings.csv ( standAlone편 확인)
배포파일 설정
* standAlone기반소스에서 아래의 정보들만 추가 및 변경
* val spark = SparkSession.builder
.appName("yarn-cluster-test").master("yarn-cluster")
.getOrCreate
* csv("hdfs:///user/ubuntu/ratings.csv")
* summary.write.format("csv").save("hdfs:///user/ubuntu/output")
배포파일 업로드
1. scp -i pem파일경로 호스트파일경로 ubuntu@원격호스트네임:원격서버경로
2. 파일질라 사용
spark-env.sh 설정 변경
* vim $SPARK_HOME/conf/spark-env.sh 실행
export HADOOP_CONF_DIR=$HADOOP_CONF_DIR
export SPARK_MASTER_HOST=maseternode(마스터노드 호스트명)
spark-submit 실행
bin/spark-submit \
--class ch2.YarnClusterTest \
--master yarn \
--deploy-mode cluster \
--driver-memory 2g \
--executor-memory 1g \
--num-executors 3 \
--executor-cores 2 \
/배포파일경로/advancedanalyticswithspark_2.11-1.0.jar
masternode:50070/explorer.html
