https://grouplens.org/datasets/movielens
데이터셋 다운로드(저 같은 데이터셋이 큰 ml-latest.zip을 선택함)
테스트 소스
importorg.apache.spark.sql.{DataFrame,Dataset,Row,SparkSession}importorg.apache.spark.sql.functions._//스파크 세션 설정
valspark=SparkSession.builder.appName("standAlone-cluster-test").getOrCreateimportspark.implicits._// csv파일 읽기
valpreview=spark.read.csv("/Users/lee/Downloads/ml-latest/ratings.csv")preview.show// option값 설정
valparsed=spark.read.option("header","true")// 파일의 첫 줄을 필드 명으로 사용
.option("nullValue","?")// 필드 데이터를 변경( "?" => null )
.option("inferSchema","true")// 데이터 타입을 추론한다.
.csv("/Users/lee/Downloads/ml-latest/ratings.csv")parsed.showparsed.countparsed.cacheparsed.groupBy("movieId").count.orderBy($"count".desc).show// createOrReplaceTempView(): 사용중인 DataFrame의 하나의 뷰를 생성한다.
valcreateView=parsed.createOrReplaceTempView("parks")spark.sql("""
SELECT movieId, COUNT(*) cnt
FROM parks
GROUP BY movieId
ORDER BY cnt DESC
""").show// describe() : numeric columns, including count, mean, stddev, min, and max의 통계를 리턴해준다.
valsummary=parsed.describe()summary.show
스탠드얼론 (싱글 머신)
1. spark-shell 실행: $SPARK_HOME/bin/spark-shell --master local
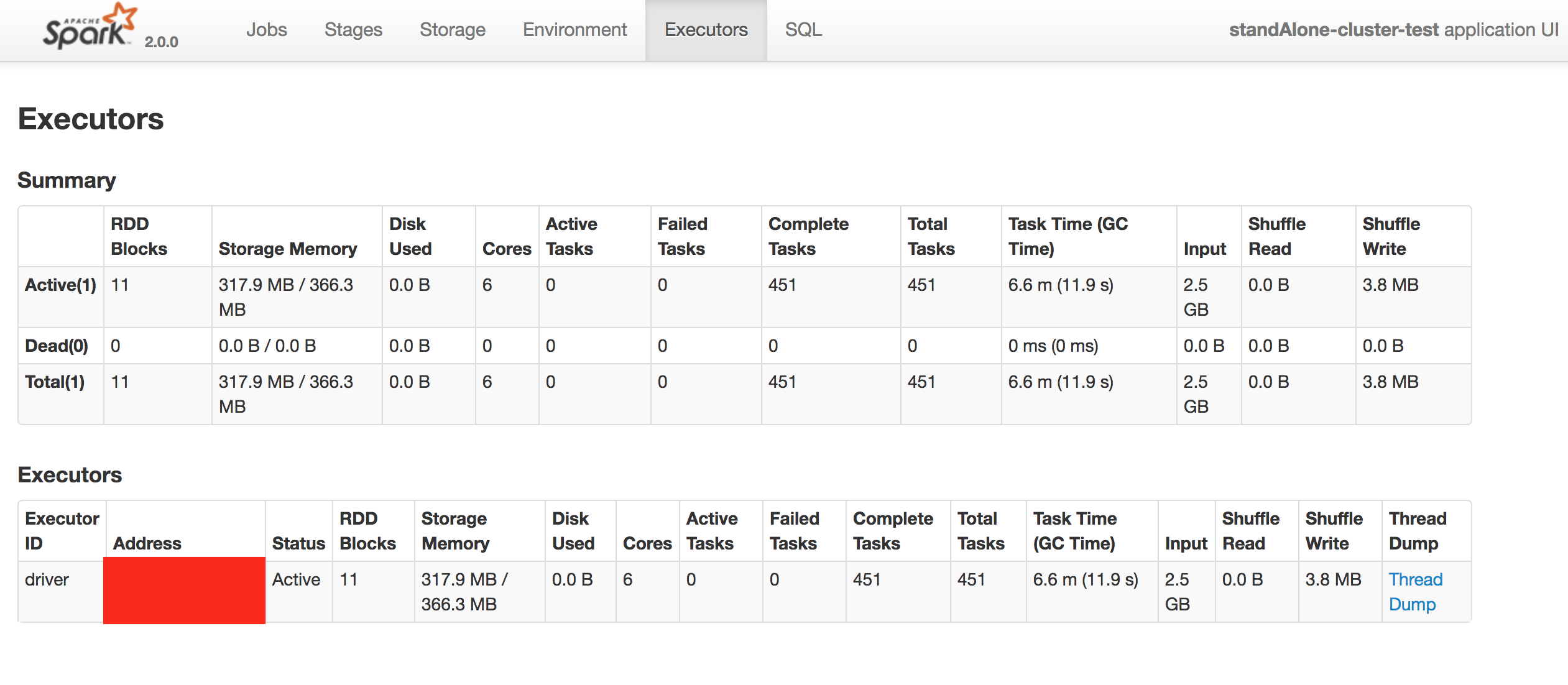
스탠드얼론 클러스터 (싱글 머신)
1. spark-shell 실행: $SPARK_HOME/bin/spark-shell --master spark://localhost:7077
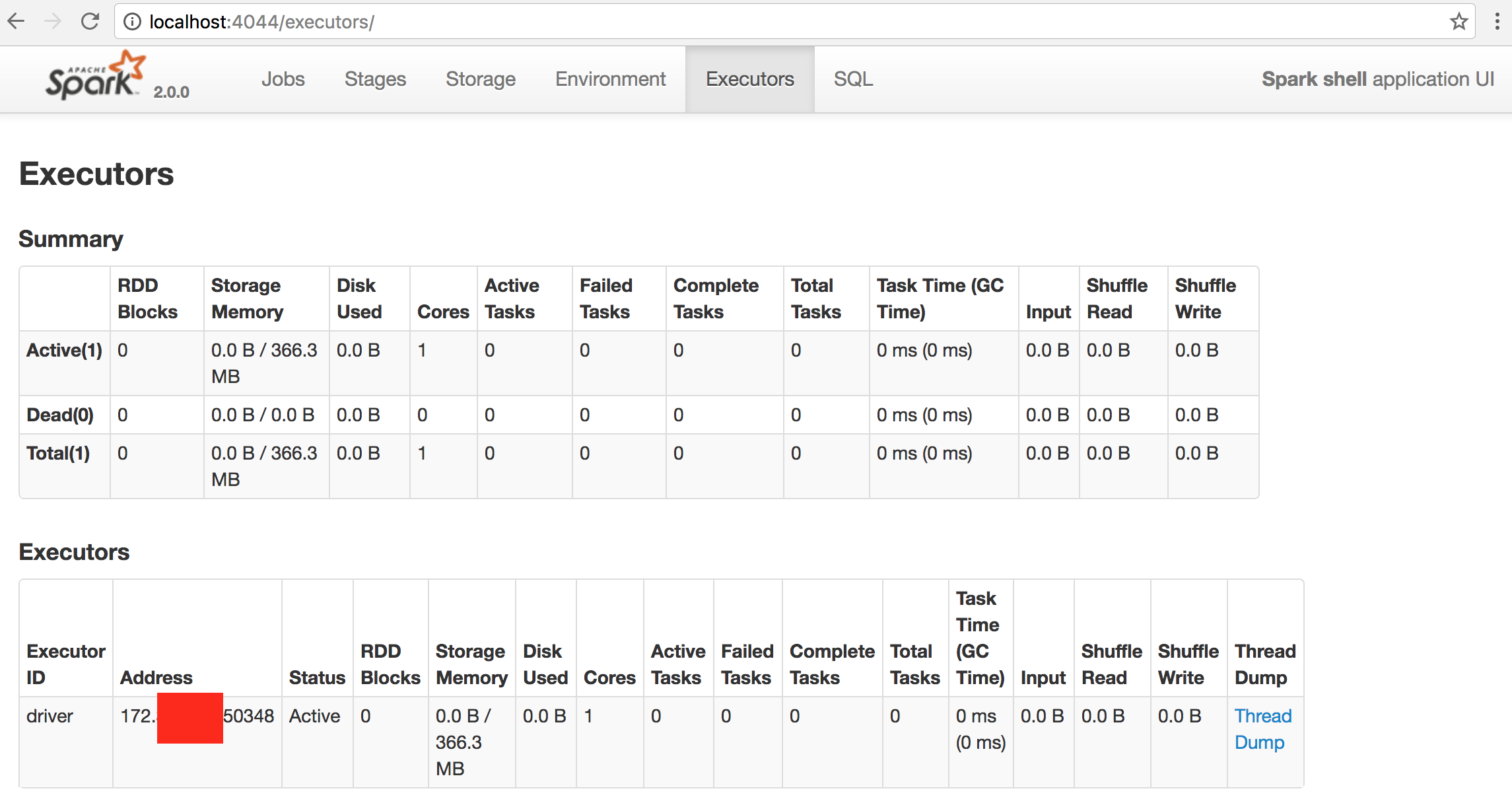
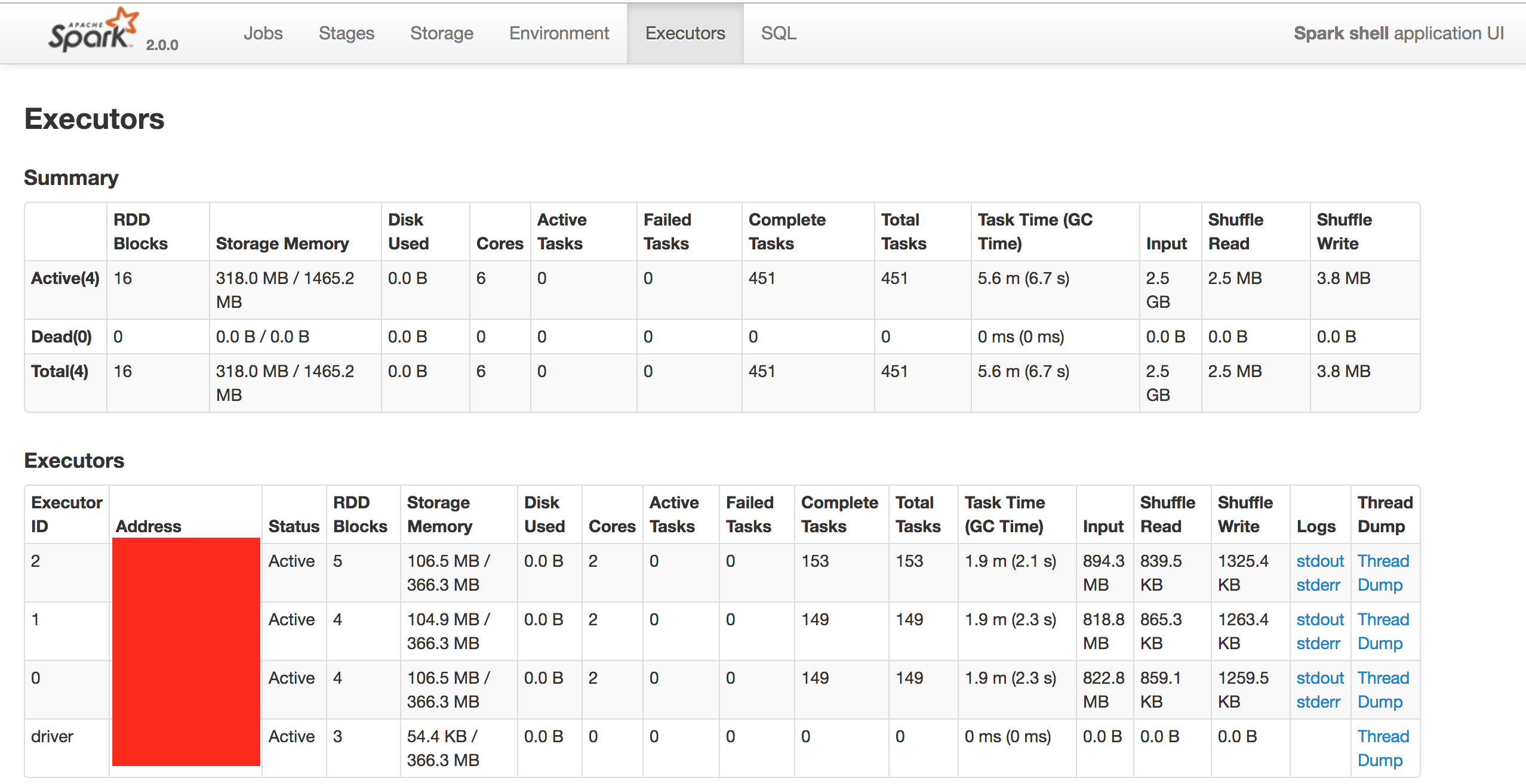
2. spark-shell 웹 UI 접속: http://localhost:4040
3. executors 카테고리 선택
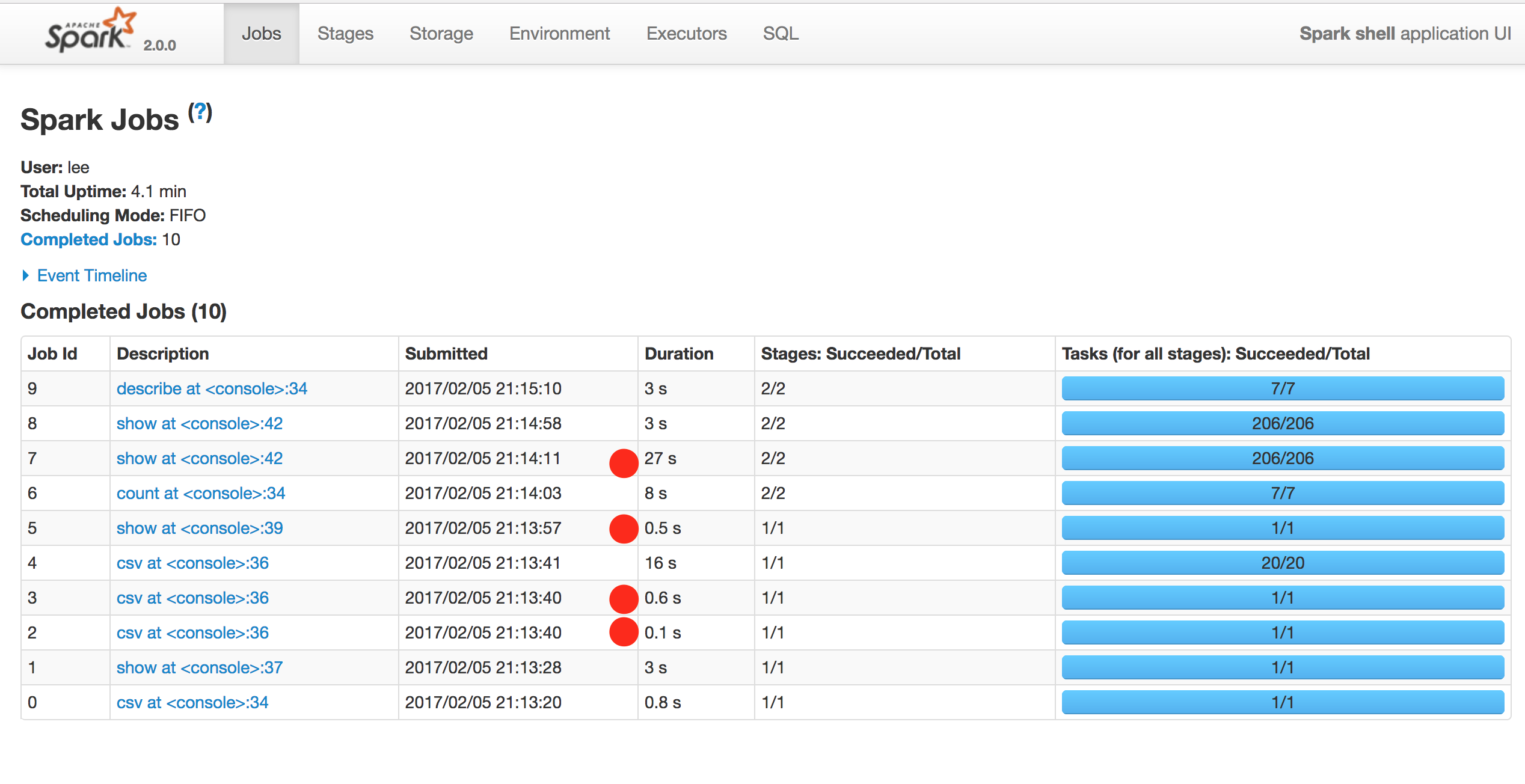
스탠드얼론 (싱글 머신) - 결과(1core)
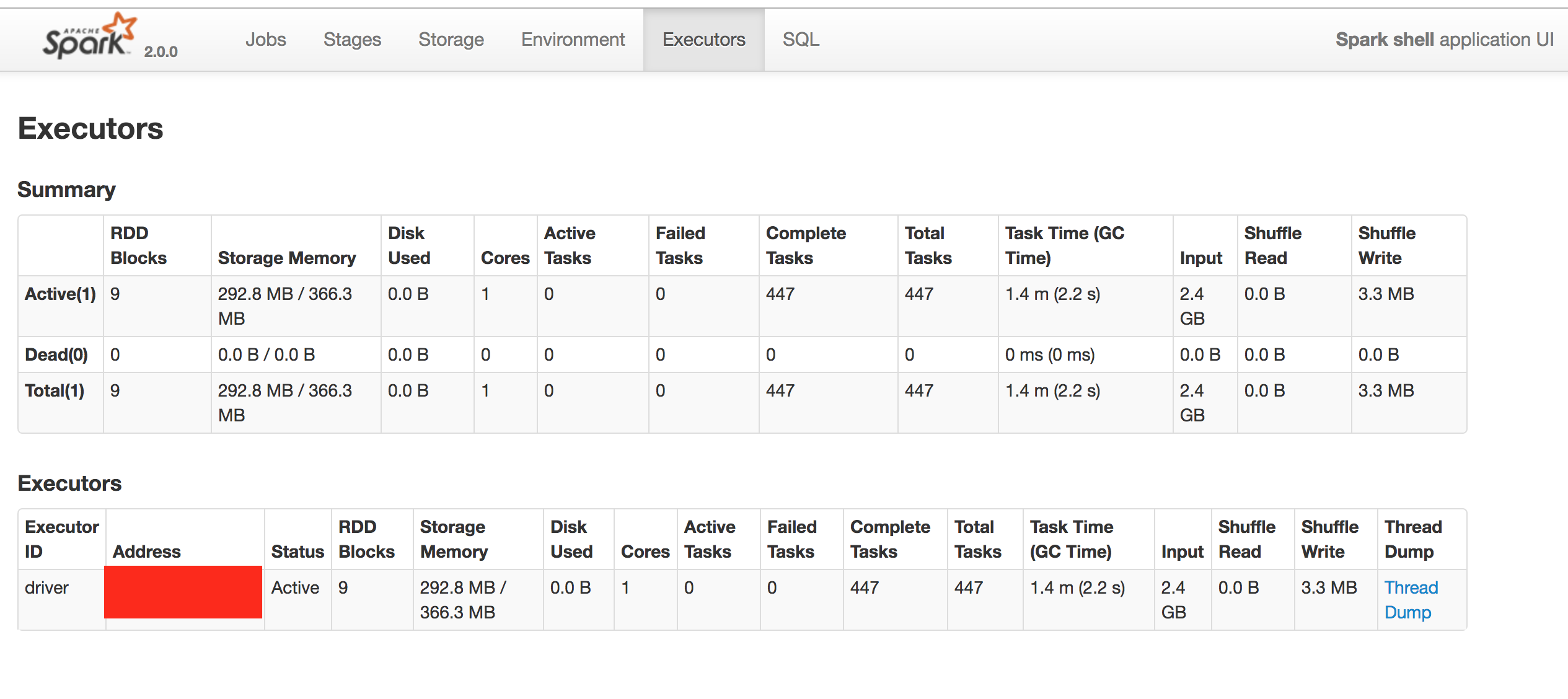
스탠드얼론 (싱글 머신) - 결과(6core)
1. 로직 변경 : appName(“standAlone-cluster-test”).master("local[6]")
2. bin/spark-submit \
--master local \
--class ch2.StandAloneTest \
배포파일.jar
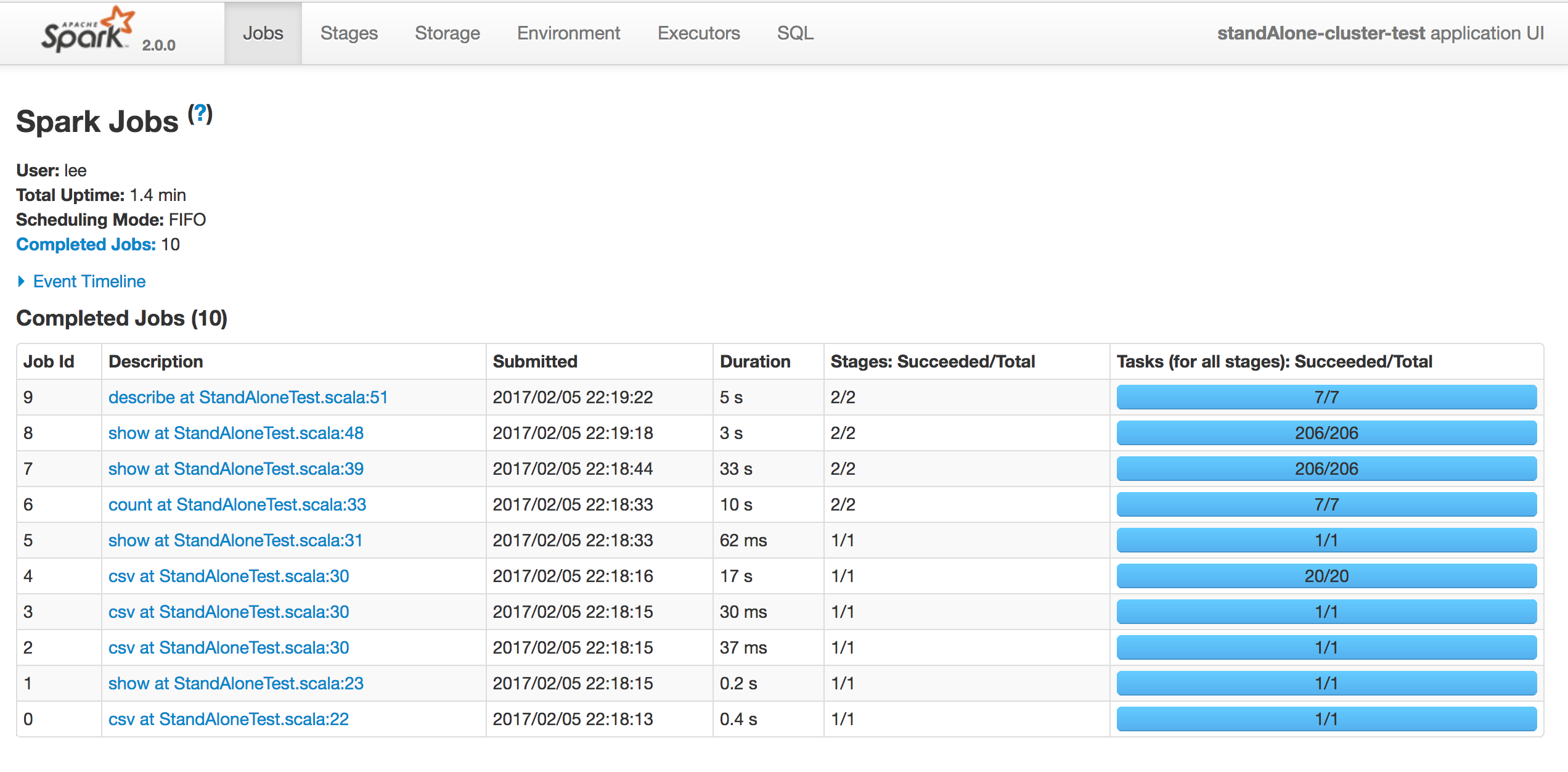
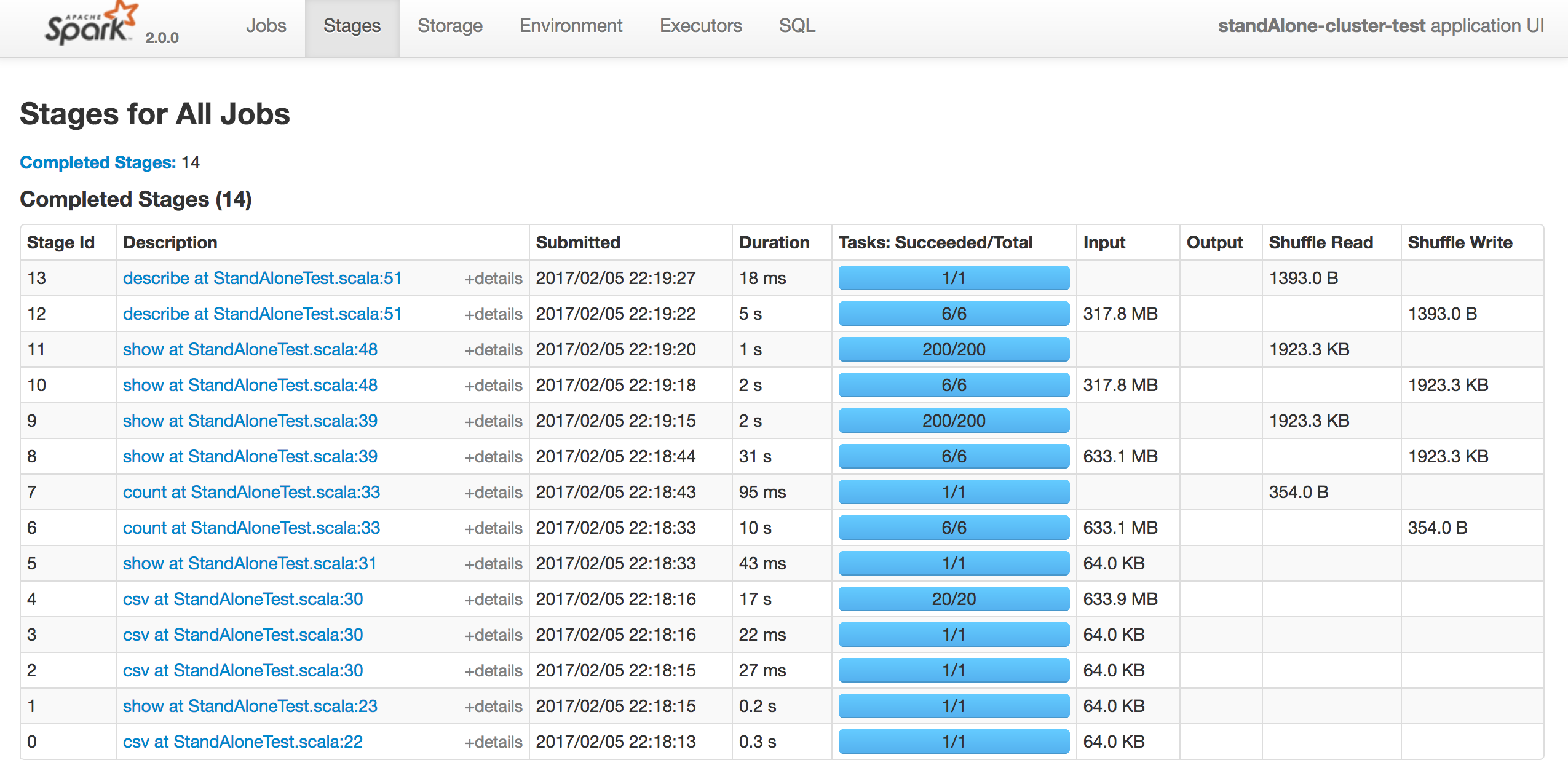
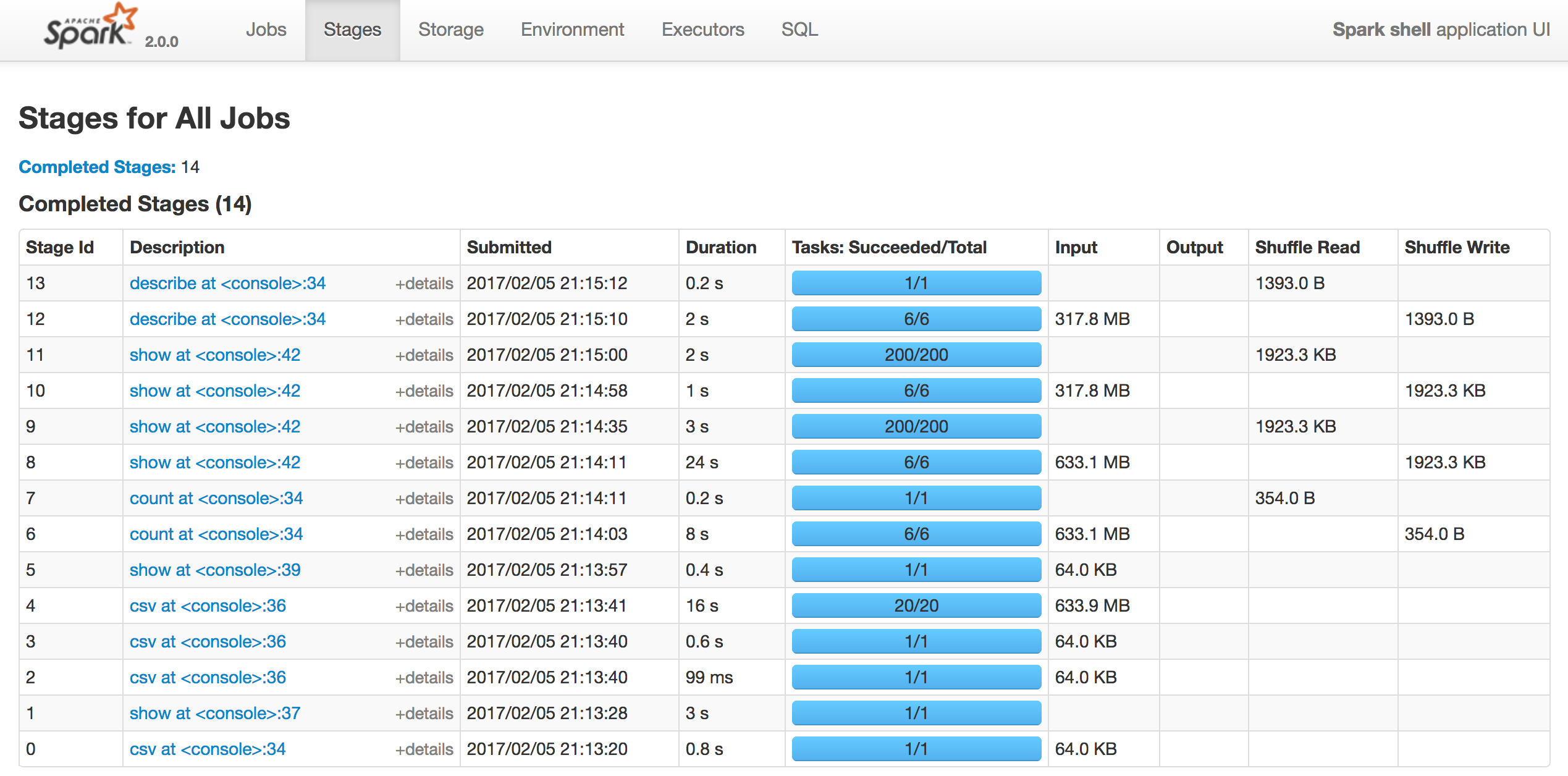
스탠드얼론 클러스터 (싱글 머신) - 결과
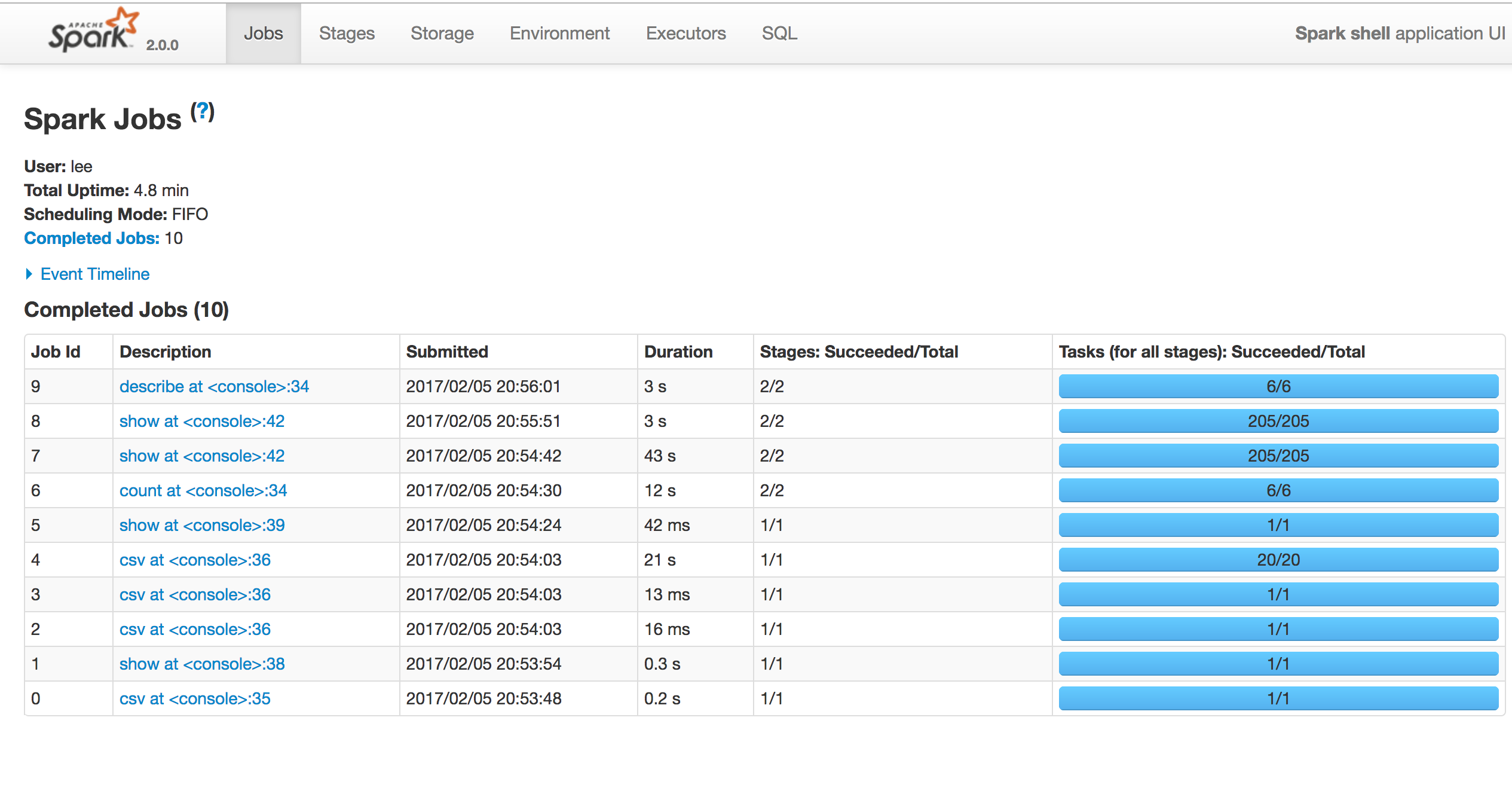
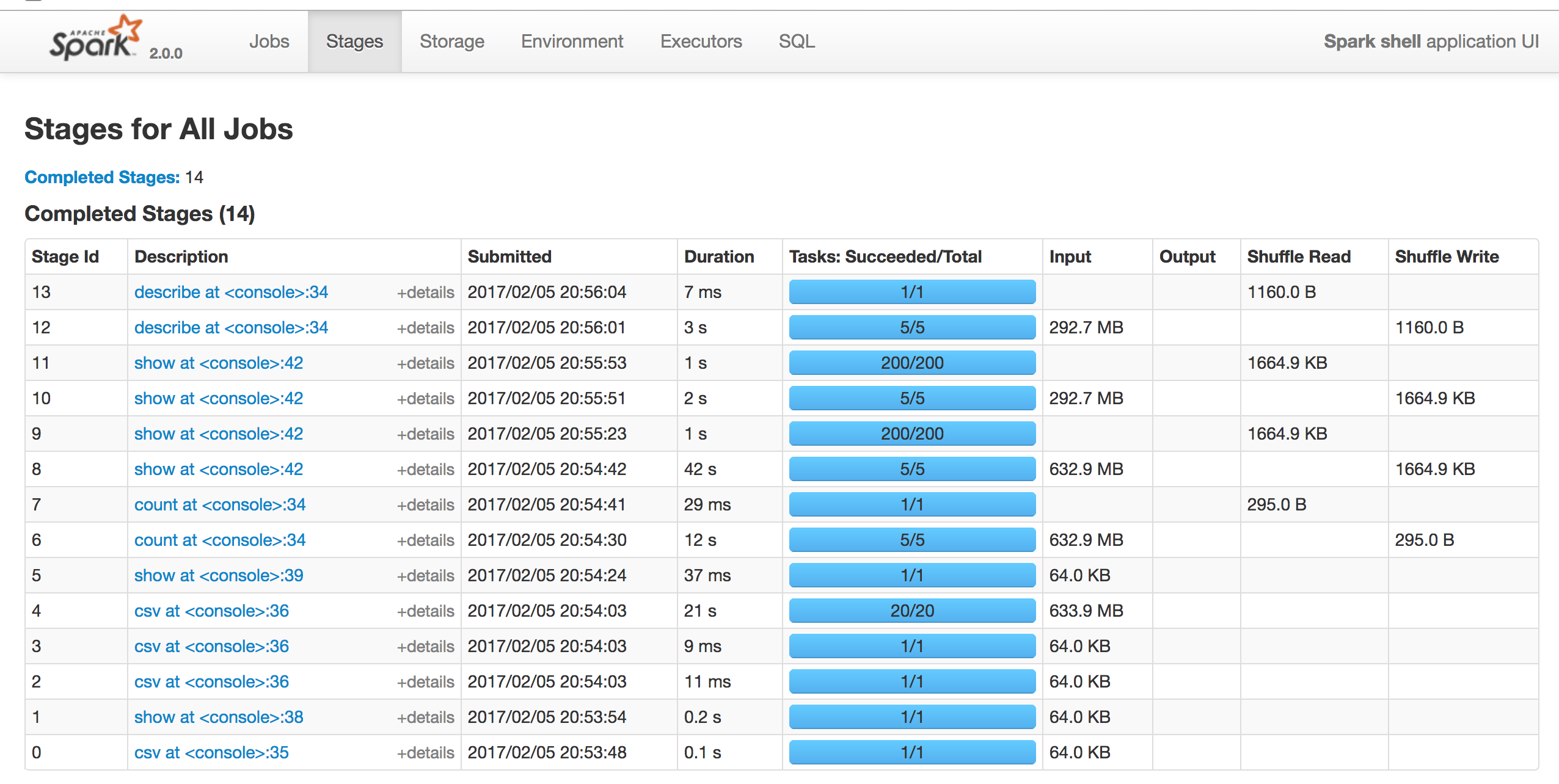
특정 Stage에서 non 클러스터에 비해 클러스터로 실행한 시간이 상당히 감소했다.(jobs에 빨간색으로 찍힌 점 )
하지만 전체 실행 시간으로 봤을땐 큰 차이가 없어 메모리/코어를 증설해야 성능 향상이 될 것 같다.